DataFrame con Pandas a partir de CSV
En este artículo veremos como crear un DataFrame en Pandas a partir de un archivo CSV. Revisaremos algunas de las técnicas para el manejo de estos archivos y la selección de elementos del DataFrame como el encabezado y la columna de ID.
En el siguiente ejemplo se muestra un archivo CSV que lista diferentes características de restaurantes.
Bar,Precio,Reserva,Tipo,Calificación
No,$$$,Si,Francesa,5
No,$,No,Tailandesa,4
Si,$,No,Hamburguesa,4
No,$,No,Tailandesa,5
No,$$$,Si,Francesa,3
Si,$$,Si,Italiana,4
Si,$,No,Hamburguesa,1
No,$$,Si,Tailandesa,2
Si,$,No,Hamburguesa,5
Si,$$$,Si,Italiana,4
No,$,No,Tailandesa,2
Si,$,No,Hamburguesa,3
Es posible leer el archivo CSV y convertirlo automáticamente en un DataFrame utilizando el método read_csv pasando la ubicación del archivo.
import pandas as pd
df = pd.read_csv('restaurantes.csv')
Por defecto la primer fila de el archivo CSV se asigna como nombre de la columnas y forma parte del encabezado del DataFrame.
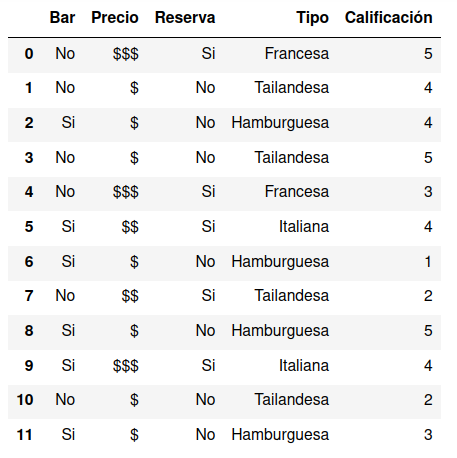
Selección de columnas
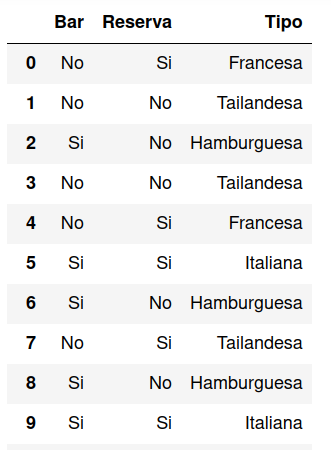
Para especificar qué columnas del archivo CSV formarán parte del Dataframe se utiliza el parámetro usecols indicando con una lista los números de columnas elegidos.
import pandas as pd
df = pd.read_csv('restaurant.csv', usecols=[0,2,3])
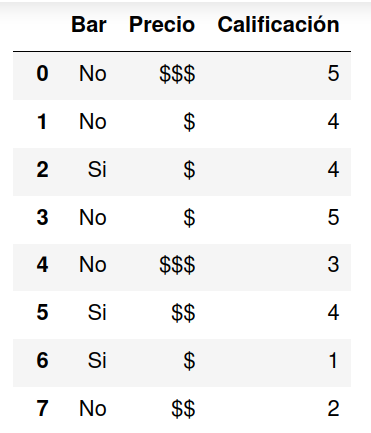
Si las columnas tienen asignados nombres también es posible seleccionarlas por nombre. Aunque los nombres pueden listarse en cualquier orden estos aparecerán en el orden en el que se los encuentra en el archivo.
import pandas as pd
df = pd.read_csv('restaurant.csv', usecols=['Precio','Bar','Calificación'])
Archivos sin encabezado
El siguiente archivo CSV no contiene una fila asignada para el encabezados. Las cuatro filas existentes corresponden a datos.
Pedro,Gonzales,32
María,Morales,12
Julio,Torres,55
Lisa,Moreno,76
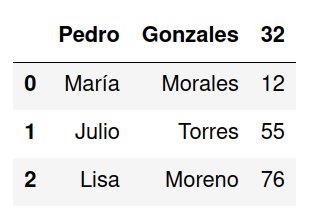
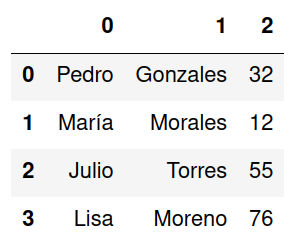
Al intentar convertir el archivo en DataFrame Pandas colocará la primer fila como nombre de la columna.
import pandas as pd
df = pd.read_csv('clientes.csv')
Para evitar este comportamiento se agrega el parámetro header configurado a None.
import pandas as pd
df = pd.read_csv('clientes.csv', header=None )
Esto indica a Pandas que debe interpretar todas las filas como datos y se le asignará a la las columnas valores numéricos.
Creación de encabezado
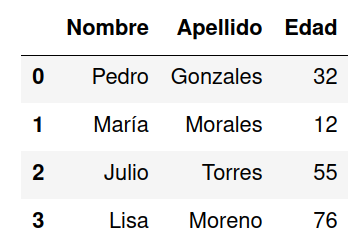
Es posible crear un encabezado durante la creación del DataFrame utilizando el atributo names y pasando una lista de los nombres de las columnas.
import pandas as pd
df = pd.read_csv('clientes.csv', header=None, names =['Nombre','Apellido','Edad'] )
Ignorar filas
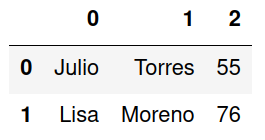
En muchas ocaciones los archivos CSV suelen tener un encabezado con varias lineas que no forman parte de los datos. Para ignorar una cantidad de filas (comenzando desde la fila o) se utiliza el parámetro skiprows indicando la cantidad de filas a ignorar.
import pandas as pd
df = pd.read_csv('clientes.csv',header=None, skiprows=2)
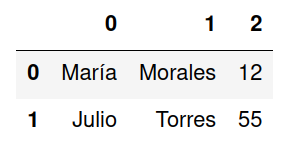
Este parámetro acepta un lista de valores True/False para configurar que fila será ignorada. Haciendo uso de la función lambda es posible especificar que filas formarán parte del DataFrame.
import pandas as pd
df = pd.read_csv('clientes.csv',header=None, skiprows=lambda x: x in [0, 3])
Configuración de separador
Aunque la mayoría de los archivos CSV separan los datos utilizando una coma(,) no es inusual encontrar archivos que utilicen otro carácter como separador.
Pedro;Gonzales;32
María;Morales;12
Julio;Torres;55
Lisa;Moreno;76
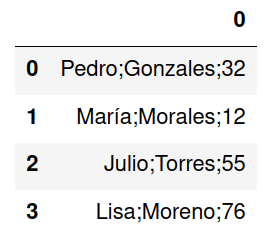
Si se intenta leer este archivo utilizando el método read_csv no se realizará la separación entre los elementos de una fila ya que por defecto se espera una coma como separador.
import pandas as pd
df = pd.read_csv('clientes.csv',header=None)
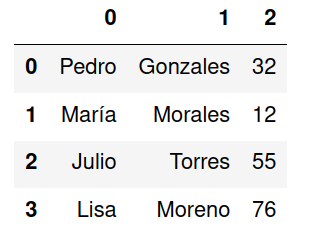
Para especificar el separador a utilizar se utiliza el parámetro sep indicando el carácter o serie de caracteres que indican la separación entre columnas.
import pandas as pd
df = pd.read_csv('clientes.csv',header=None, sep=';')
Configuración de columna ID
En el siguiente archivo CSV se listan nombres de aves que tienen un valor ID asignado.
ID,Nombre
16,Colibri
18,Águila
19,Gaviota
20,Cuervo
23,Gorrión
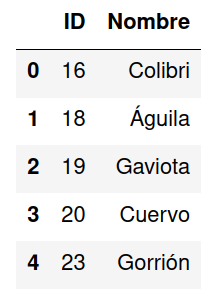
Cuando se intenta convertir el archivo en un DataFrame Pandas automáticamente le asigna un ID a cada fila comenzando desde el índice 0.
import pandas as pd
df = pd.read_csv('aves.csv')
Para que este ID corresponda con una columna en particular de los datos se utiliza index_col y se especifica la columna a utilizar. Para esto puede utilizarse tanto el índice de posición de la columna como el nombre de la misma.
import pandas as pd
df = pd.read_csv('aves.csv', index_col=0)
import pandas as pd
df = pd.read_csv('aves.csv', index_col='ID')

Lectura por lotes o chunks
Cuando se trabaja con archivos de gran tamaño es una buena práctica procesarlos por lotes o chunks para evitar problemas de memoria. Para esto se utiliza el parámetro chunksize que indica el tamaño de cada lote en cantidad de registros o filas. Para leer los datos completamente se debe ciclar por cada lote y procesarlos individualmente.
import pandas as pd
for lote in pd.read_csv('ventas.csv', chunksize=2000):
process_chunk(lote)
Reconocimiento de valores faltantes
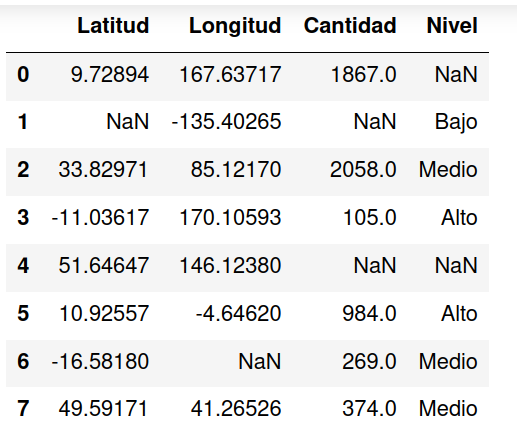
En este ejemplo puede observarse que todas las columnas tienen valores faltantes expresados de diferentes maneras. Las columnas de latitud y longitud etiqueta los valores faltantes como Unknown, cantidad lo expresa con un guion y la columna nivel lo hace con el texto NONE.
Latitud,Longitud,Cantidad,Nivel
9.72894,167.63717,1867,NONE
Unknown,-135.40265,-,Bajo
33.82971,85.12170,2058,Medio
-11.03617,170.10593,105,Alto
51.64647,146.12380,-,NONE
10.92557,-4.64620,984,Alto
-16.58180,Unknown,269,Medio
49.59171,41.26526,374,Medio
Al mostrar el DataFrame resultante de la lectura directa del archivo CSV estos valores no son reconocidos como faltantes sino que se consideran un valor más.
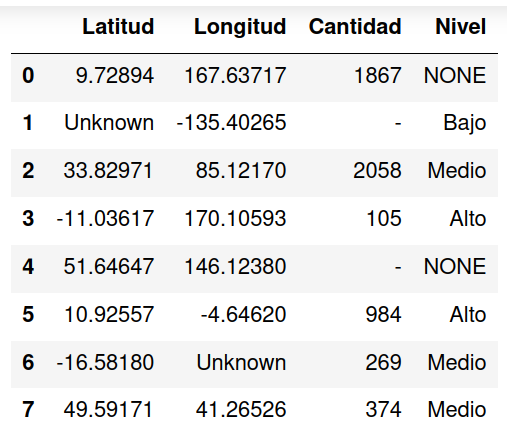
Para identificar correctamente estos valores como faltantes se utiliza el atributo na_values. Utilizando una lista es posible configurar el valor que identifica la falta de valor para cada columna.
import pandas as pd
df = pd.read_csv('coordenadas.csv', na_values=['Unknown','Unknown','-','NONE'])
El DataFrame resultante identifica correctamente los valores faltantes mostrándolos como NaN.
En este artículo hemos visto cómo crear un DataFrame con Pandas a partir de un archivo CSV. Hemos visto cómo manejar, modificar y crear encabezados y cómo definir el ID como una columna. Finalmente hemos explicado la forma de manejar archivos CSV de gran tamaño y la manera de identificar valores faltantes.