grep y las expresiones regulares básicas y extendidas
En esta oportunidad aprenderemos el uso de las expresiones regulares básicas y extendidas en la terminal de comandos de GNU/Linux, usando grep, tema importante para todo administrador de sistemas, y necesario para quienes deseen certificar LPIC-1.
Muchos comandos hacen uso de expresiones regulares. Las expresiones regulares son plantillas que se pueden definir para utilidades como grep o egrep, y que se pueden usar como patrones para filtrar texto. Entendiendo las expresiones regulares básicas y su uso en algunas utilidades amplían muchísimo las habilidades en el uso de la línea de comandos.
Usando grep
grep es un poderoso comando que usa expresiones regulares para ayudar al filtrado de texto. Antes de pasar a las expresiones regulares veamos algunos usos básicos de grep.
Si quisiéramos listar todas las líneas del archivo /etc/group que contengan la palabra «diego» podríamos hacer lo siguiente:
grep diego /etc/group
Esto resuelve el requisito, y muestra por pantalla las líneas del archivo /etc/group que contienen la palabra «diego», y cumple la sintaxis básica del comando grep:
grep [OPCIONES] PATRON [ARCHIVO...]
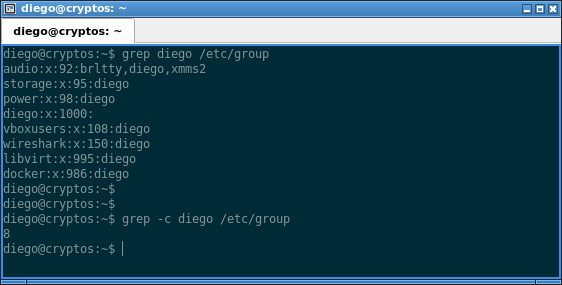
El comando grep soporta algunas opciones interesantes. La opción -c muestra la cantidad de ocurrencias del patrón en el archivo:
grep -c diego /etc/group
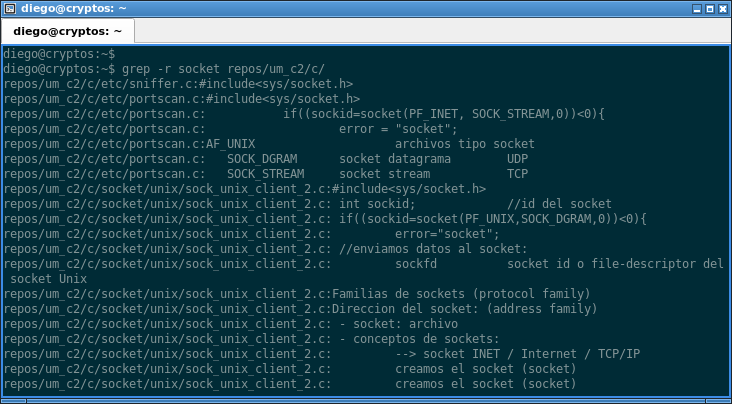
La opción -r permite buscar un patrón en un directorio de manera recursiva. Por ejemplo, el siguiente comando:
grep -r socket repos/um_c2/c/
Va a buscar la palabra «socket» en todos los archivos de ./repos/um_c2/c/, va a mostrar el archivo y la línea dentro del mismo donde se encuentra el patrón buscado.
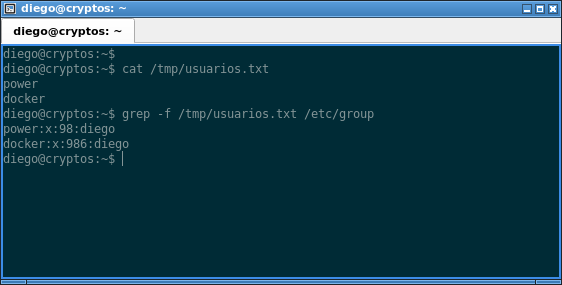
Otra funcionalidad interesante es la de buscar varios patrones en uno o varios archivos. Supongamos que tenemos un archivo de texto denominado /tmp/usuarios.txt, que contiene lo siguiente:
power
docker
Y quisiéramos buscar dentro del archivo /etc/group aquellas líneas que contengan las palabras «power» o «docker». Podríamos hacer lo siguiente:
grep -f /tmp/usuarios.txt /etc/group
La opción -F permite especificar que el patrón no es una expresión regular, sino una cadena de texto. Así, grep -F es equivalente a fgrep.
Otra opción interesante es -E, o --extender-regexp, para utilizar las denominadas «expresiones regulares extendidas», pero escapa al alcance de este artículo.
BRE: expresiones regulares básicas
Las expresiones regulares básicas, BRE, incluyen:
.*(punto asterisco) para representar múltiples caracteres..(punto) para representar un caracter.[a, e, i, o, u]para representar algunos caracteres (no incluye las comas)[A-z]para presentar un rango de caracteres.^para representar el inicio de una línea (registro que se encuentra en el inicio de una línea).$para representar el fin de línea (registro que se encuentra al final de una línea).
Expresiones como [x, y, z] o [a-j] se denominan expresiones de corchetes, mientras que ejemplos como ^juncotic o juncotic$ se denominan expresiones ancla y sirven para buscar un patrón al inicio o fin de una línea respectivamente.
Veamos algunos ejemplos.
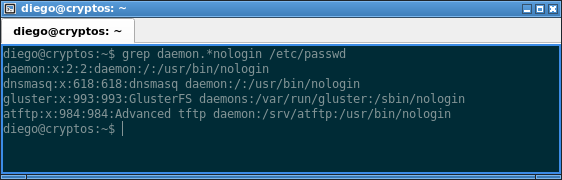
Filtrando las líneas de /etc/passwd que contienen las palabras «daemon» y «nologin» separadas por uno o más caracteres:
grep daemon.*nologin /etc/passwd
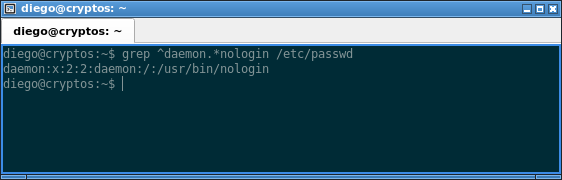
De esas líneas, ahora filtremos aquellas en las que la palabra «daemon» se encuentra al inicio de la línea:
grep ^daemon.*nologin /etc/passwd
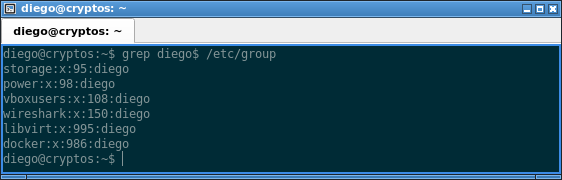
O filtremos las líneas de /etc/group que contengan la palabra «diego» al final de la línea:
grep diego$ /etc/group
Para filtrar aquellas líneas que no incluyan un determinado patrón se puede usar la opción -v. Por ejemplo, para mostrar aquellas líneas de /etc/passwd que no incluyan la palabra nologin al final de la línea se puede usar:
grep -v nologin$ /etc/passwd
Clases de caracteres en grep
Existe un grupo especial de expresiones de corchetes denominadas clases de caracteres. Se trata de expresiones predefinidas que pueden utilizarse como atajos. Su interpretación depende de la configuración local del sistema, y cargada en la variable de entorno LC_CTYPE.
Las clases de caracteres más comunes son:
| Clase | Descripción |
[:blank:] | Coincide con caracteres en blanco, tales como un espacio o un tabulador. |
[:digit:] | Coincide con caracteres numéricos. Equivale a [0-9] |
[:lower:] | Coincide con caracteres alfabéticos en minúscula. Equivale a [a-z] |
[:upper:] | Coincide con caracteres alfabéticos en mayúsculas. Equivale a [A-Z] |
[:punct:] | Coincide con signos de puntuación tales como !, #, $ y @ |
Veamos algunos ejemplos. Supongamos que tenemos el archivo /tmp/archivo.txt con el siguiente contenido:
hola
mundo $ 555
123 456
bye
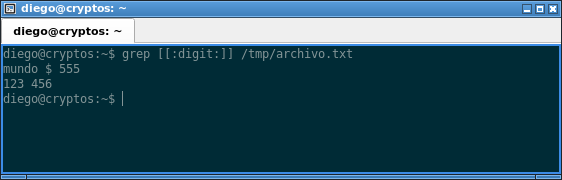
Podemos filtrar únicamente aquellas líneas que contengan números con el siguiente comando:
grep [[:digit:]] /tmp/archivo.txt
Nótese el uso de corchetes dobles. Una clase de caracteres debe especificarse dentro de una expresión de corchetes comunes.
Nota: si prestamos atención, veremos que la primer línea de la salida contiene el caracter $. En el caso de que quisiéramos filtrar únicamente esa línea, deberíamos escapar el caracter $ con dos barras invertidas \\ para que no sea considerado como caracter de fin de línea:
grep \\$ /tmp/archivo.txt
ERE: Expresiones regulares extendidas
Las expresiones regulares extendidas, o ERE (Extended regular expressions) permiten armar patrones más complejos. Por ejemplo, un símbolo vertical de tubería | permite especificar dos posibles palabras o conjunto de caracteres como patrón. También pueden usarse los paréntesis () para designar expresiones regulares adicionales como subexpresiones.
Para que el comando grep reconozca estas expresiones extendidas debe usarse el modificador -E, o simplemente el comando egrep. Veamos algunos ejemplos simples.
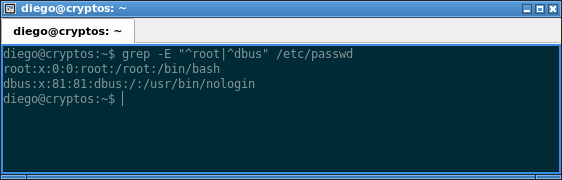
grep -E "^root|^dbus" /etc/passwd
Este comando filtra, del archivo /etc/passwd, aquellas líneas que incluyan la palabra «root» o «dbus» al principio de la línea.
egrep "(daemon|Server).*nologin" /etc/passwd
Este comando incluye una subexpresión entre paréntesis. La subexpresión va a filtrar aquellas líneas que incluyan la palabra «daemon» o la palabra «Server» (o ambas, no es excluyente). Luego, .*nologin indica cualquier caracter seguido de la palabra «nologin». El resultado final será el conjunto de líneas que contengan las palabras «daemon» o «Server» seguidas de la palabra «nologin», separadas ambas por cualquier caracter o conjunto de caracteres.
Conclusión
Hemos aprendido a utilizar algunas expresiones básicas y extendidas junto con el comando grep (y sus variantes fgrep y egrep) para realizar filtrados más avanzados en archivos de texto.
Estos filtrados son perfectamente válidos para utilizar mediante pipe y la salida de un comando de terminal.
Las expresiones extendidas mostradas son muy básicas, pero sirven a modo introductorio. En futuros artículos se ampliará este tema, ya que resultan sumamente útiles para tareas de filtrado avanzadas.
Este contenido es uno de los requisitos para rendir el examen 101 de la certificación internacional LPIC-1, y forma parte del curso que impartimos a tal efecto.
Espero les sea de utilidad!