Estadística con Python
En este artículo veremos las funciones estadísticas incluidas en el módulo statistics de Python para obtener promedios y tendencias dentro de una distribución de valores.
El módulo statistic de Python provee una serie de funciones para el cálculo estadístico de valores reales. Aunque existen otras librerías especializadas en análisis estadístico,(NumPy, SciPy, Matlab, etc) que responden a necesidades específicas el módulo integrado de Python es suficiente para muchos casos.
Medias
Media o promedio
El promedio o media aritmética se calcula utilizando la función mean, que toma como parámetro una lista de los valores sobre los cuales se quiere calcular la tendencia media. Este valor se calcula como la suma de todos los valores divididas entre la cantidad de valores existentes.
El promedio representa el valor central de la población y es una de las medidas más utilizadas. Esta medición, sin embargo, se ve afectada por valores extremos y por lo tanto puede no ser representativa de la centralidad de los valores.
from statistics import mean
data = [1,1,1,2,3,3,4,5,5,5,5,6,7,8,8,8,8,9,9,9,9,9,10]
print(mean(data))
#5.869565217391305
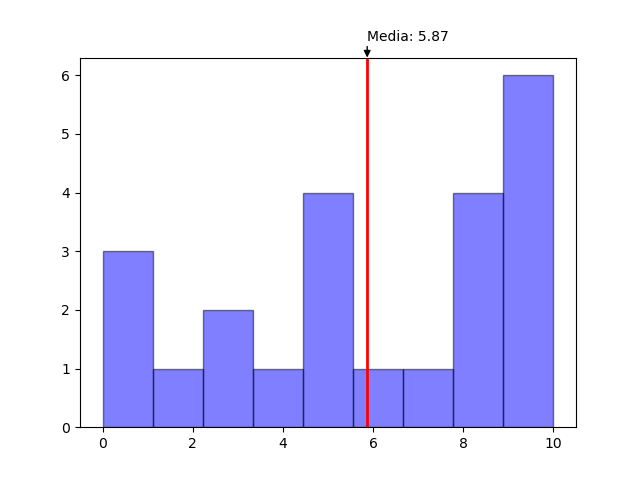
En este ejemplo puede observarse como la media se encuentra orientada a la derecha al verse visto afectada por los valores extremos superiores.
Media geométrica
La media geométrica calcula la tendencia central de los valores de una distribución. Se calcula a partir de la multiplicación de todos los valores a cuyo resultado se le aplica una raíz cuadrada. Puede utilizarse el método geometric_mean para calcular la media geométrica pasando por argumento la lista de valores.
from statistics import geometric_mean
data = [1,1,1,2,3,3,4,5,5,5,5,6,7,8,8,8,8,9,9,9,9,9,10]
print(geometric_mean(data))
#4.795910352885917

En este ejemplo puede observarse como la media se ve menos afectada por los valores extremos que con el promedio.
Media con pesos
El módulo statistics permite calcular el promedio de una serie de valores asignando a cada valor un peso diferente. De esta manera es posible asignarle mayor valor en el resultado final del cálculo del promedio dependiendo del valor.
Para realizar una media con pesos se utiliza el método fmean al que se le pasará como argumento la lista de datos a promediar y la lista de pesos donde cada peso corresponde al valor correspondiente de la otra lista.
from statistics import fmean
data = [1,1,1,2,3,3,4,5,5,5,5,6,7,8,8,8,8,9,9,9,9,9,10]
pesos = [0.02,0.02,0.03,0.1,0.02,0.02,0.03,0.02,0.01,0.08,0.12,0.09,0.02,0.03,0.01,0.06,0.04,0.07,0.02,0.05,0.09,0.03,0.02]
print(fmean(data,pesos))
#6.0

Media armónica
La media armónica es similar a la aritmética y se calcula como el número de observaciones dividido por la suma de los complementos de los valores. Esta media se utiliza en casos donde se quieran promediar trayectos con longitudes iguales pero con tiempos diferentes. Para calcularla se utiliza el método harmonic_mean que toma como argumento la lista de valores y opcionalmente una lista de pesos.
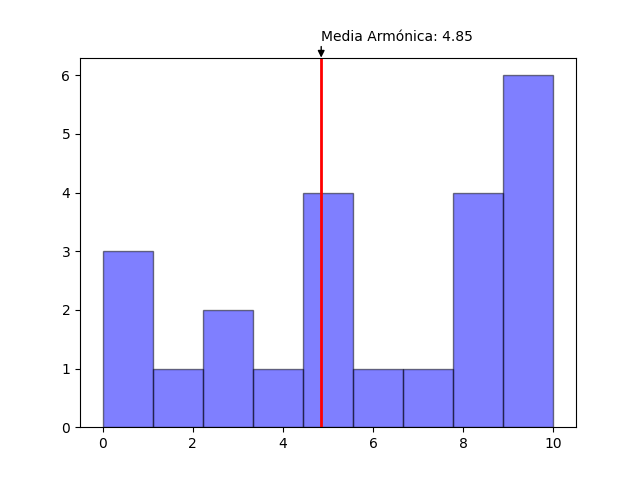
A diferencia de la media aritmética la media armónica no se ve especialmente afectada por valores extremos altos ya que los valores sumados son solamente el complemento de los valores originales. Por esta misma razón se ve muy afectada por los valores extremos bajos.
from statistics import harmonic_mean
data = [1,1,1,2,3,3,4,5,5,5,5,6,7,8,8,8,8,9,9,9,9,9,10]
pesos = [1,2.2,0,1,4,5,18,2,9,2,7,8,9,1,0,5,6,7,8,10,1,1,2]
print(harmonic_mean(data,pesos))
#4.849228166631423
Medianas
Mediana simple
La mediana simple devolverá el valor ubicado en el centro de la lista de valores ordenados. A diferencia de las medias, las medianas no se ven afectadas por los valores extremos. En el caso que un solo valor ocupe la posición central de la muestra este será devuelto, en el caso de ser dos números (ya que la cantidad de valores es par) se devolverá el promedio de estos.
Para obtener la mediana se utiliza el método median que toma como argumento una lista de valores.
from statistics import median
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
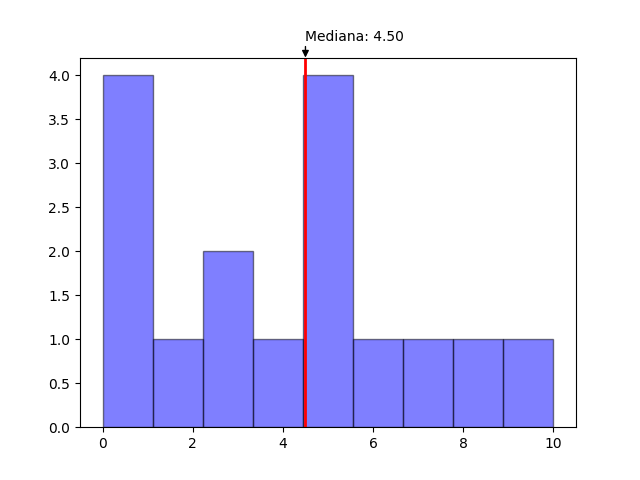
print(median(data))
#4.50
Mediana baja
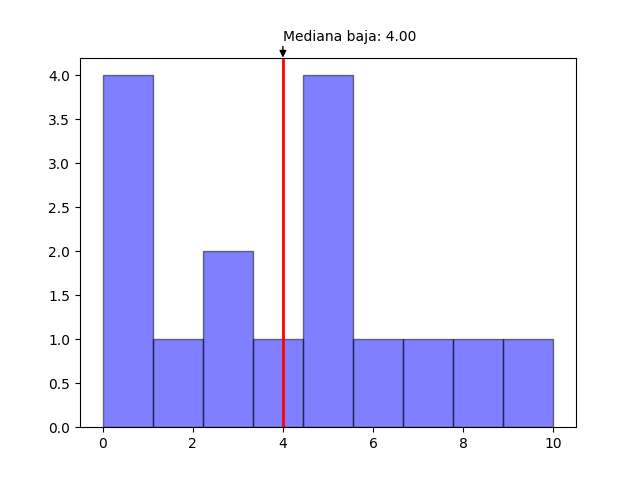
La mediana baja funciona de manera similar a la media simple, en el caso que un solo valor ocupe el lugar central este será devuelto. Pero, a diferencia de la mediana simple, si existen dos valores en el lugar central entonces se devolverá el más bajo de los dos. Para obtener esta mediana se utiliza median_low y se le pasa una lista como argumento.
from statistics import median_low
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(median_low(data))
#4
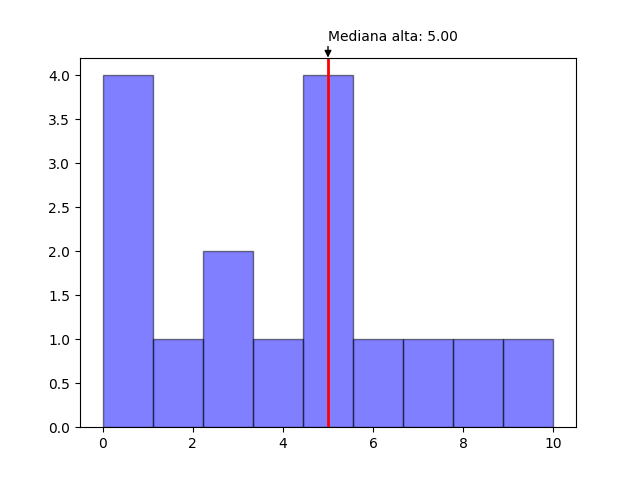
Mediana alta
La mediana alta funciona de manera opuesta a la mediana baja, en el caso que un solo valor ocupe el lugar central este será devuelto. Pero si existen dos valores en el lugar central entonces se devolverá el más alto de los dos. Para obtener esta mediana se utiliza median_high y se le pasa una lista como argumento.
from statistics import median_high
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(median_high(data))
#5
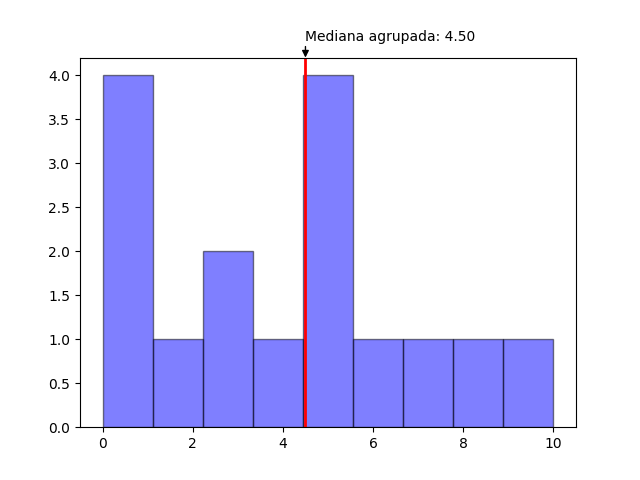
Mediana agrupada
La mediana agrupada se diferencia del resto en que no realiza su cálculo utilizando cada valor individual de la lista de valores sino que es calculado agrupando los valores en intervalos y utilizando la frecuencia de cada intervalo. Por defecto el método median_grouped interpreta cada valor de la lista como el punto medio del intervalo.
De manera predeterminada el intervalo es de uno (1).
from statistics import median_grouped
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(median_grouped(data))
#4.5
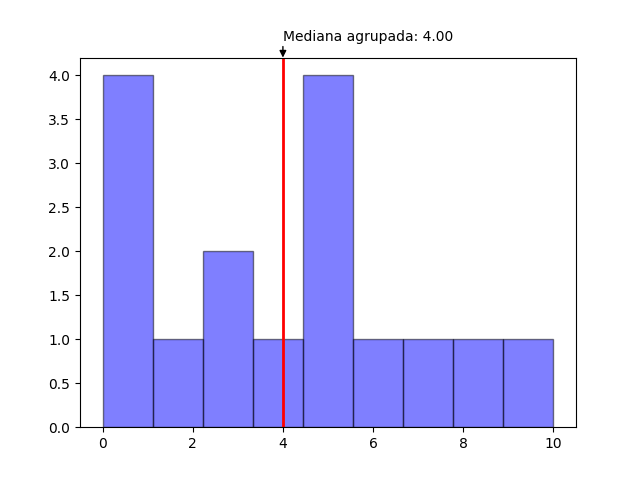
Es posible especificar un ancho de intervalo distinto utilizando el argumento interval.
from statistics import median_grouped
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(median_grouped(data, interval = 2))
#4.00
Modas
Moda simple
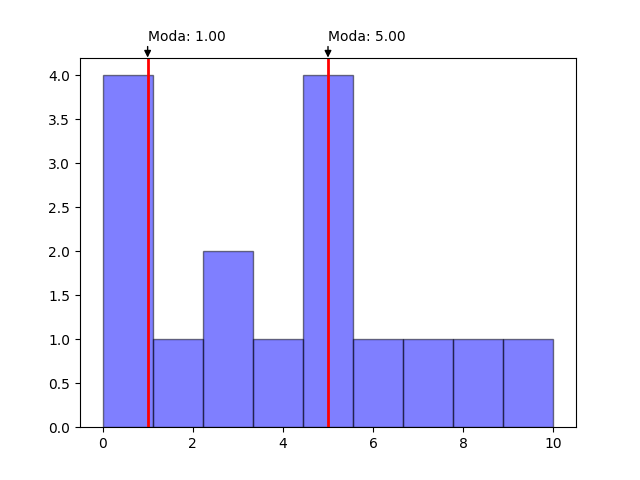
La moda simple retorna el valor más común (aquel que se repite una mayor cantidad de veces) de una muestra de datos discretos. En el caso que existan más de un valor con la misma frecuencia de aparición se devolverá el primer valor de todos los encontrados.
Para calcular la moda de una lista de valores se utiliza el método mode
from statistics import mode
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(mode(data))
#1.00
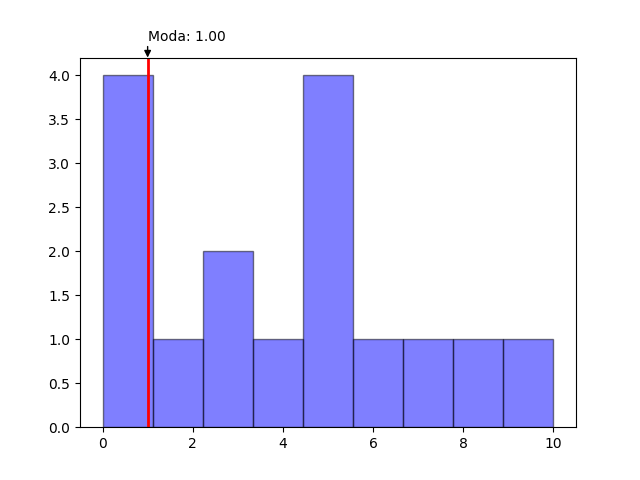
En este ejemplo puede verse como tanto los valores 1 y 5 tienen la mayor frecuencia de aparición con un valor de 4 pero el método mode selecciona 1 por ser el primer valor encontrado.
Multimoda
El método multimode funciona de manera similar al de moda excepto que retornará una lista con todos aquellos valores que compartan el número de frecuencia de aparición máxima de la muestra.
from statistics import multimode
data = [1,1,1,1,2,3,3,4,5,5,5,5,6,7,8,10]
print(multimode(data))
#[1, 5]
En este artículo hemos mostrado el funcionamiento de alguna de las funciones estadísticas más comunes del módulo statistic en Python para el cálculo de promedios, medianas y modas. Espero que les sirva.