Load Average: ¿Qué significa la carga de procesamiento en Linux?
Hoy analizaremos el significado del concepto de promedio de carga de procesos, o load average, en sistemas Linux… tres valores que vemos en la salida de comandos como uptime, top o htop.
Respondiendo consultas de mi curso de Administración Linux Completo (LPIC-1), he decidido crear este artículo para poder explayarme más en la explicación.
¿Qué es el load average, o promedio de carga?
Primero veamos dónde encontramos estos valores, con algunos ejemplos.
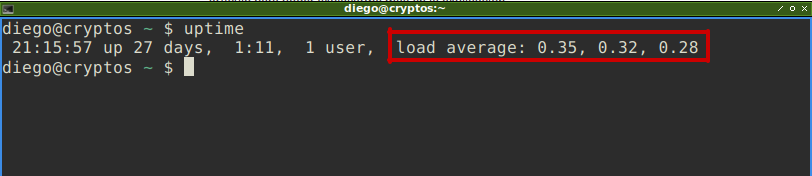
uptime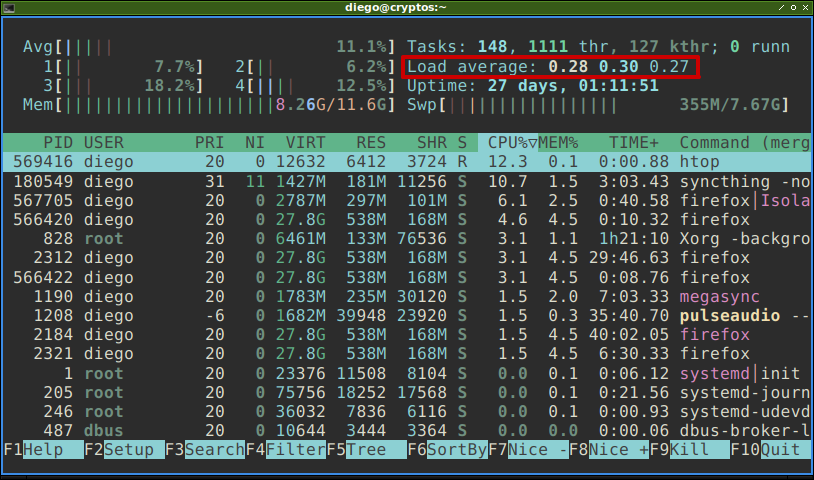
htop.En ambos ejemplos, tanto uptime como htop nos muestran el load average, o promedio de carga de procesamiento del sistema, como una serie de tres valores, veamos qué significan.
Estos tres valores representan la carga de procesamiento del sistema en tres periodos de tiempo distintos: un minuto, cinco minutos, y quince minutos respectivamente.
Los valores altos indican que el equipo está sobrecargado, pero esto no nos dice nada… ¿qué valores serían correctos, o estarían dentro de los parámetros normales? ¿cuándo deberíamos preocuparnos y actuar sobre las configuraciones del sistema?
Veamos un ejemplo simple para ilustrarlo mejor.
📚 ¿Querés saber más de GNU/Linux y sus detalles? Sumate a nuestro curso!
Un ejemplo sencillo
Encontré una interesante analogía que compara la carga de trabajo con el tráfico en una calle [1].
Supongamos un procesador mononúcleo. Un núcleo de procesamiento podría interpretarse como un puente por el que circulan autos.
Imaginemos ahora que somos administradores de un puente por donde pasan esos autos. Si el puente está muy congestionado de tráfico, habrá muchos autos en la calle esperando para cruzar. Podríamos medir el grado de congestión de tráfico en el puente usando una métrica sencilla: cantidad de autos transitando el puente en este momento.
El puente tendrá una capacidad máxima de autos transitándolo, así, si no hay autos cruzando, los conductores de la calle sabrán que puede cruzar el puente ni bien lleguen al mismo. Si hay autos en el puente, los conductores sabrán que, dependiendo de cuántos autos estén en el puente, puede que tengan demoras para cruzarlo.
Pongamos números a esta métrica:
- 0.00 indica que no hay tráfico en el puente, por lo que un conductor que vea un valor de 0.00 sabrá que puede cruzar inmediatamente.
- 1.00 indica que el puente está en su capacidad máxima, el conductor sabe que deberá esperar al llegar al puente.
- >1.00 implica que el puente está sobrecargado con más autos de los que puede soportar, es decir, está completo, y tenemos autos en la calle esperando que se libere para poder cruzar.
Veamos un ejemplo numérico.
Si en el puente caben 10 autos como máximo, y llega un conductor al puente y el valor de la métrica de carga le indica «0.50«, implica que el puente tiene 5 autos, por lo que puede entrar directamente porque está medianamente desocupado.
Si llega y la métrica le indica «1.00» ya sabe que tiene que esperar a que se desocupe un poco, porque está en su capacidad máxima, es decir, tiene 10 autos.
Si llega y la métrica le indica «2.50«, el puente está sobrecargado, es decir, tiene 25 autos esperando. En la realidad, serían 10 autos esperando en el puente, y 15 más esperando entrar al puente.
Volcando el ejemplo en la CPU
Si volvemos a la CPU, los procesos del sistema Linux utilizan porciones de tiempo de la CPU para ejecutarse. Es decir, el tiempo total de procesamiento de la CPU se divide en porciones de tiempo (slots temporales), y cada proceso utiliza una de esas porciones una vez por vez, para poder ejecutarse.
Salvando detalles, una simplificación sería la siguiente. Un core de procesamiento podría ser nuestro puente, mientras que los procesos ocupando slots de tiempo del procesador serían los autos transitando el puente. La capacidad máxima del puente estaría dada por la cantidad de slots temporales que tiene o, lo que es equivalente, la cantidad de procesos en cola de ejecución.
Ahora bien, en una computadora, con muchos procesos entrando y saliendo del procesador permanentemente, la cantidad de «autos en el puente» de manera instantánea no nos sirve de mucho, ya que va a cambiar a gran velocidad.
Una mejor métrica es un promedio de procesos en un intervalo de tiempo, en porcentaje.
Ahora, ¿qué intervalo de tiempo representa mejora la carga del sistema?
Aquí tenemos tres valores que son clave: el promedio del último minuto, el promedio de los últimos 5 minutos, y el promedio de los últimos 15 minutos.
Así, con el promedio del último minuto sabríamos la carga «casi» instantánea del sistema, y los promedios de 5 y 15 minutos nos ayudarán a entender esa evolución de la carga, si está incrementándose de a poco, o se está reduciendo, o cuál es la carga permanente dentro del sistema.
Si ejecutamos el comando uptime, o vemos la salida de htop, podremos apreciar estos tres valores.
El primero, 0.35 en este ejemplo, representa el promedio de carga del último minuto en el sistema. El segundo, 0.32, el promedio en los últimos 5 minutos, mientras que el último, 0.28. el promedio de carga de los últimos 15 minutos.
📚 ¿Querés saber más de GNU/Linux y sus detalles? Sumate a nuestro curso!
Entendiendo el load average, o carga del sistema
Si en el último minuto tenemos un valor alto, no necesariamente estaría mal. Esto puede deberse a que estamos ejecutando alguna tarea de alta cantidad de procesamiento, y durante su ejecución, el promedio del último minuto aumentó.
Ahora, si en los últimos 5 minutos, o peor, en los últimos 15 minutos, la carga del sistema es elevada, esto podría indicar algún problema. En general una carga elevada constante del >70% de la capacidad total de carga del sistema indicaría que estamos al límite de procesamiento.
En este caso sería conveniente analizar la situación, por qué hay tantos procesos en ejecución consumiendo CPU, puede tratarse de alguna anomalía de algún servicio o aplicación.
Si se trata de un servidor, si la carga máxima esté al límite de manera permanente, y esto sea por el normal funcionamiento de los servicios, sería conveniente evaluar un upgrade del hardware del servidor para reducir esta carga de procesamiento.
Como nota, no es cuestión de intentar llevar la carga a cero, una carga promedio en un sistema da cuenta de las tareas que ejecuta, y que el sistema no está ocioso. Pero una carga constante elevada indicaría que, en el caso de requerir ejecutar tareas extra tendríamos poco margen con el procesador en su estado actual, y esta nueva tarea podría ralentizar el normal funcionamiento del sistema, afectando a los servicios que está brindando.
Load average en procesadores multinúcleo o múltiples procesadores
En el caso de que el sistema cuente con un procesador con varios núcleos de procesamiento, lo cual es normal hoy en día, o cuente con múltiples procesadores, configuraciones comunes en servidores, los valores de load average van a cambiar.
Si tenemos un solo core de procesamiento, el valor de carga completa sería 1.00. Si tenemos dos cores de procesamiento, la carga completa ahora sería de 2.00, y así sucesivamente.
Independientemente de la cantidad de procesadores que tengamos, lo que cuenta son los cores de procesamiento. Así, por ejemplo, si tenemos dos procesadores de 8 núcleos cada uno, el valor de carga completa de trabajo sería de 16.00, puesto que dispondríamos de 16 núcleos de procesamiento.
Por ejemplo, si en mi computadora tengo 4 cores de procesamiento, el valor de carga completa sería de 4.00. Así, si el promedio de los últimos 15 minutos en mi sistema estuviera permanentemente cercano a 3.00 (aproximadamente un 70% de la carga total), debería analizar la posibilidad de un upgrade.
Como conclusión, la carga completa de nuestro sistema coincidirá con la cantidad de núcleos de procesamiento que tengamos.
¿Cuántos núcleos tiene mi sistema?
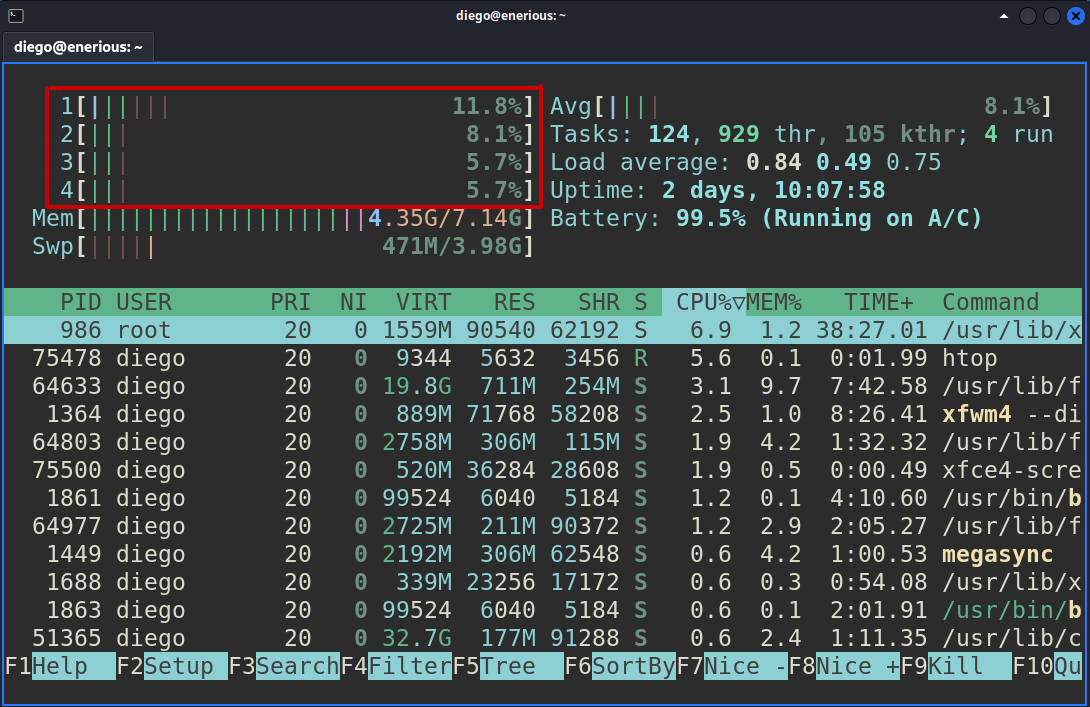
Esto puede responderse rápidamente ingresando a herramientas como top o htop. En la siguiente captura he marcado los cores de procesamiento de mi procesador: son 4.
Otra forma de verlo es a través del archivo /proc/cpuinfo, que nos da información del hardware de procesamiento que estamos utilizando.
Este archivo se divide en bloques, donde cada bloque nos da información de cada uno de los núcleos de procesamiento. Veamos un ejemplo:
└─$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 142
model name : Intel(R) Core(TM) i7-7500U CPU @ 2.70GHz
stepping : 9
microcode : 0xf4
cpu MHz : 799.982
cache size : 4096 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb pti ssbd ibrs ibpb stibp tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp vnmi md_clear flush_l1d arch_capabilities
vmx flags : vnmi preemption_timer invvpid ept_x_only ept_ad ept_1gb flexpriority tsc_offset vtpr mtf vapic ept vpid unrestricted_guest ple pml ept_mode_based_exec
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_multihit srbds mmio_stale_data retbleed gds
bogomips : 5799.77
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
[...]
En esta salida vemos el primer bloque, correspondiente al core número 0, y a continuación el inicio del bloque del core número 1. Los bloques tienen la misma estructura y campos, y si se trata del mismo procesador, generalmente los valores también serán coincidentes.
En este caso particular se trata de un procesador Intel(R) Core(TM) i7-7500U de cuatro núcleos, pero si no queremos leernos todo el archivo, simplemente podemos hacer uso de las ventajas de la shell y los pipes para contar cuántos bloques hay.
└─$ grep processor /proc/cpuinfo | wc -l
4
Aquí estoy filtrando de este archivo las líneas que tienen la palabra «processor», y de esa salida, cuento cuántas líneas son. El resultado es la cantidad de bloques, 4.
Conclusiones
Ahora ya entendemos mejor qué representan estos valores de load average, o promedio de carga, en salidas de htop, top o uptime.
Cabe resaltar que, si se trata de equipos de red, la mayoría de las herramientas genéricas de monitoreo registran estos valores históricamente, de modo que podemos analizar la carga de procesamiento de un servidor y su evolución, y configurar alarmas cuando el promedio de carga permanente del sistema supere determinado umbral.
A propósito de esto, les comparto un script de Python que me compartió Carlos Correa en la red social Mastodon. Escribió un script en Python para cargar en un Ansible desde varios hosts, y envía alertas por email cuando el load average de dichos hosts supera un determinado umbral.
Va el link del repositorio Git, espero que les sirva! Y gracias Carlos por tu colaboración!
https://github.com/charliec114/monitors/blob/main/load-avg/check_status.py
Espero que les haya resultado útil!
Hasta la próxima!
📚 ¿Querés saber más de GNU/Linux y sus detalles? Sumate a nuestro curso!
