Mapa de memoria de un proceso en Linux
Hoy analizaremos qué es un mapa de memoria de un proceso en Linux, particularmente de un programa escrito en C, y usaremos herramientas como gcc, size o pmap para comprenderlo.
Un mapa de memoria, en inglés, memory map, o también podemos encontrarlo como memory layout, es una estructura de datos que indica al sistema operativo cómo está distribuida la memoria de un proceso, los segmentos que la componen, y los datos almacenados en cada uno de ellos.
Cuando ejecutamos un programa en Linux, se crea un mapa de memoria con una estructura particular (que veremos en seguida), y dentro se carga toda la información de dicho programa: variables inicializadas, variables no inicializadas, segmentos de memoria dinámica, la pila, y, por supuesto, el código binario de la aplicación (o una parte de el).
Sin entrar demasiado en detalles del núcleo, particularmente Linux utiliza una gestión de memoria basada en una combinación entre dos técnicas bien conocidas: segmentación y paginación.
Las páginas de memoria son de tamaño fijo, por ejemplo, 4 KiB (podemos leer el tamaño de la página con el comando getconf PAGESIZE), mientras que la segmentación implica segmentos de tamaño variable.
Linux divide el mapa de memoria de un proceso en segmentos de diferentes tamaños, cada uno dividido, a su vez, en páginas de tamaño fijo.
Veamos cuál es la estructura de este mapa de memoria, con ejemplos de código escrito en lenguaje C, ya que es un lenguaje de medio nivel que permite manipular la memoria de manera flexible. Además, la mayoría de las aplicaciones que corren sobre el núcleo Linux están escritas en C 🙂
Mapa de memoria, o «Memory Layout», de un proceso
El mapa de memoria de un proceso se divide generalmente en 6 segmentos, a saber:
- Argumentos de la línea de comandos y variables de entorno.
- Stack o pila del proceso.
- Heap o espacio para almacenar segmentos de memoria dinámica.
- Datos no inicializados, o BSS (Block Started by Symbol)
- Datos inicializados.
- Segmento de texto (código binario de un programa)
La estructura puede representarse de esta forma:
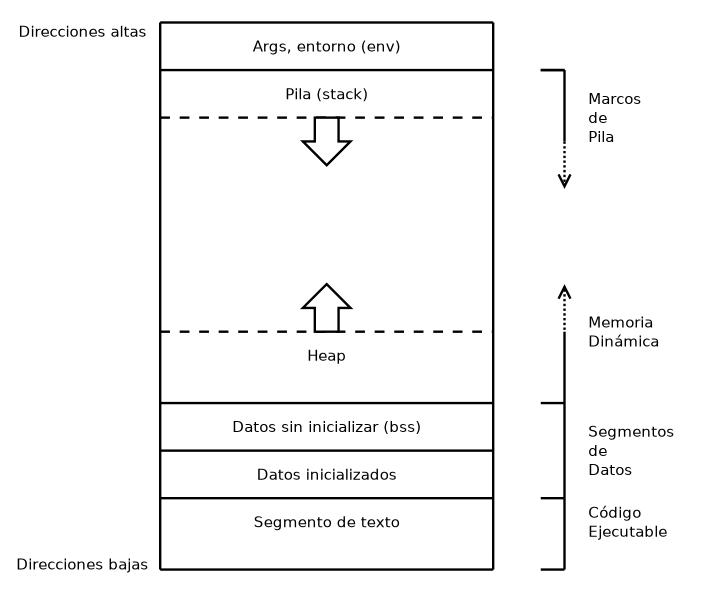
Algunos detalles de cada uno de estos segmentos.
Segmento de Pila o Stack
En este segmento se almacenan las variables locales de las funciones, los argumentos pasados a cada función llamada, y los punteros de retorno de las mismas.
Cuando se llama a una función se crea un marco de pila, se almacenan variables locales, argumentos y la dirección de retorno de la función. Cuando la función termina, se carga como siguiente instrucción la dirección de retorno, de modo que la ejecución continúe por donde iba antes de llamar a la función, y se procede a eliminar el marco de pila.
Segmento de Heap
En este segmento se almacena la memoria dinámica creada por el proceso (malloc(), calloc(), realloc() por ejemplo).
Cuando se reserva una posición para memoria dinámica el programa adquiere dicho espacio desde el heap. Si se libera dicha memoria (free()), se reduce el espacio ocupado dentro del heap.
Cuando se libera espacio de memoria dinámica se devuelve al heap, pero no a la memoria del sistema operativo, por lo que el heap puede que comience a fragmentarse.
Segmentos de datos inicializados
Contiene las variables globales y estáticas del programa, que a su vez fueron inicializadas con valores distintos de cero. Este segmento puede clasificarse como de sólo lectura y de lectura-escritura.
Así, este segmento almacenaría variables como las siguientes:
char cadena[] = "Hola Mundo"; //global
int contador = 1; //global
const int num = 5; //global
Las primeras dos se almacenan como datos de lectura-escritura, mientras que la última lo hace como sólo lectura.
Segmento de datos no inicializados
Este segmento, también conocido como BSS (heredado de lenguaje ensamblador) almacena todas las variables globales y estáticas que no están inicializadas a cero o no tienen un valor de inicialización en el código fuente. Algunos ejemplos son los siguientes:
int num; //global
static int x=0;
Segmento de texto
Este segmento almacena las instrucciones ejecutables del programa, por lo que también se lo denomina segmento de código.
Almacena la representación en código de máquina de las instrucciones del programa. Este segmento en general puede ser compartido entre diferentes procesos, ya que no se modifica, y si contiene código de librerías compartidas no es necesario duplicarlo en memoria.
Generalmente es un segmento de sólo lectura para prevenir que un proceso modifique accidentalmente código del programa que le dio origen.
Los ejemplos valen más que mil palabras
Para los siguiente ejemplos usaremos el comando size, que en su salida muestra el tamaño del segmento de texto, de datos inicializados, y el bss.
Tomemos como punto de partida el siguiente código fuente de C:
#include<stdio.h>
int main(){
return 0;
}
Compilemos el código y veamos la salida del comando size:
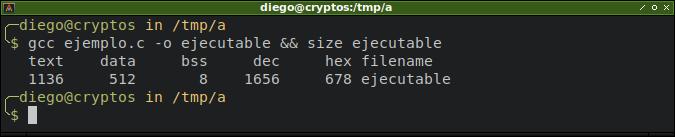
Se ve que el segmento de datos contiene 512 bytes, mientras que el bss solamente 8 bytes.
Creemos ahora, por ejemplo, una variable global, de tipo double:
#include<stdio.h>
double numero;
int main(){
return 0;
}
Veamos la salida:
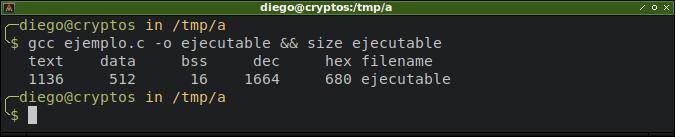
Aquí se ve que el bss aumentó 8 bytes. Esto es correcto puesto que la variable global no está inicializada, y una variable de tipo double en C ocupa 8 bytes en memoria.
Veamos ahora qué pasa si la inicializamos con un valor distinto de cero:
#include<stdio.h>
double numero = 123;
int main(){
return 0;
}
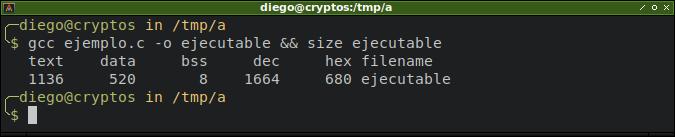
Aquí se ve que re redujo en 8 bytes el bss, ya no tenemos esa variable no inicializada. Sin embargo, se incrementó en 8 bytes el segmento de datos inicializados.
Veamos qué pasa ahora si definimos una variable estática dentro de la función main(). Como sabemos, debería incrementarse el tamaño del bss:
#include<stdio.h>
double numero = 123;
int main(){
static double otronumero;
return 0;
}
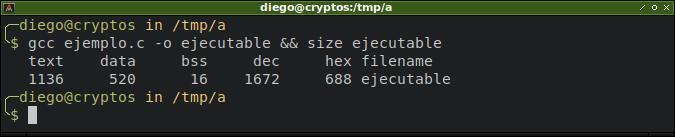
Lo dicho 🙂
Si la inicializamos, ahora el espacio vuelve a ser consumido en el segmento de datos inicializados.
#include<stdio.h>
double numero = 123;
int main(){
static double otronumero=321;
return 0;
}
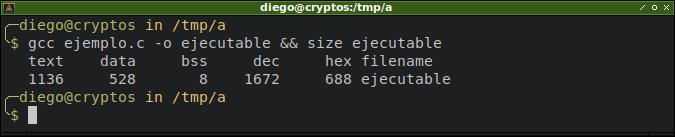
pmap: buena forma de leer el mapa de memoria completo
Un interesante comando para leer el mapa de memoria de un proceso en ejecución es pmap.
pmap tiene varios modificadores y niveles de verbosidad en la salida, veremos algo simple para orientarnos.
Algunos ejemplos. Supongamos que tenemos este programa sencillo:
#include<stdio.h>
char cadena[8192*10];
int main(){
getchar();
return 0;
}
Si compilamos y analizamos la salida del comando size veremos lo siguiente:
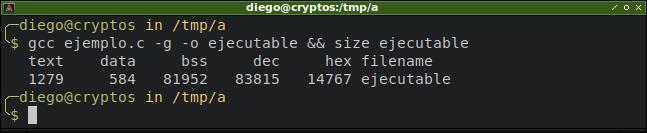
Como puede observarse, el segmento de datos no inicializados (bss) contiene 80 KiB de datos, el arreglo del 80 KiB definido de manera global.
Si ejecutamos el código éste se detendrá en la penúltima línea, getchar(), esperando que presionemos una tecla. Si lo dejamos corriendo y en otra terminal ejecutamos el comando pmap pasando por argumento el PID de nuestro ejecutable, veremos lo siguiente:
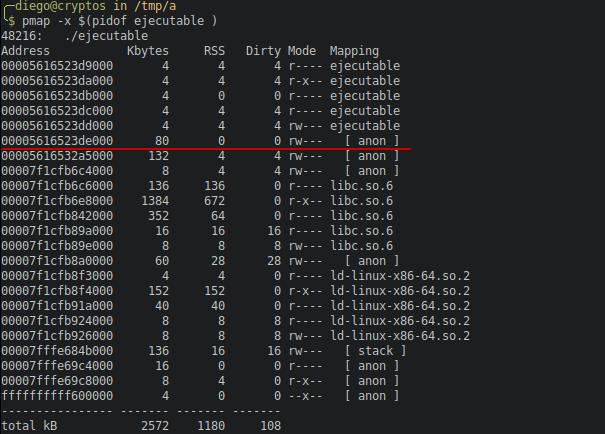
La línea marcada indica esta parte de la memoria. Una región definida como anónima (mapeo anónimo). Se llama anónima a la memoria mapeada no asociada a archivos en el disco (sí, se puede mapear un archivo de disco directamente en memoria, pero eso es otra historia).
Las columnas representan lo siguiente:
- Address: la dirección de inicio de la posición de memoria en cuestión.
- Kbytes: tamaño de esa región en KiB.
- RSS: Resident set size, parte de la memoria realmente en RAM.
- Dirty: estado de las páginas de memoria.
- Mode: permisos de acceso a esa región de memoria por parte del proceso.
- Mapping: el nombre de la app o librería asociada a esa región de memoria.
La línea marcada indica que tenemos un mapeo anónimo de 80 KiB.
Inicialicemos la memoria con un valor, y analicemos la salida de size y de pmap nuevamente.
#include<stdio.h>
char cadena[8192*10] = "hola";
int main(){
getchar();
return 0;
}
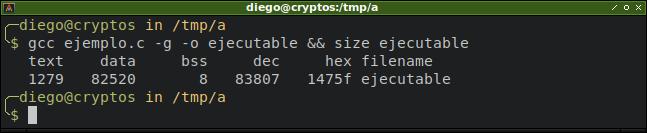
El comando size nos muestra que los 80 KiB que antes estaban en el segmento bss ahora han pasado al segmento de datos inicializados.
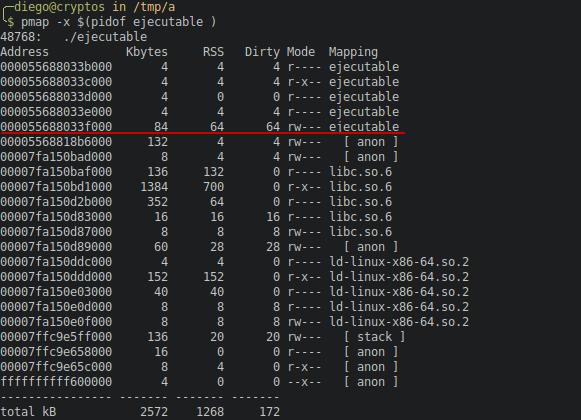
La salida de pmap muestra que ahora el segmento ya no es anónimo, ha pasado a datos inicializados, y se sumó a los 4 KiB que ya teníamos ahí.
Conclusiones: mapa de memoria
Hemos llegado al final!
Hemos realizado un breve recorrido por los conceptos de mapa de memoria de procesos en Linux, y analizamos muy por arriba algunas salidas de pmap.
Este comando da para más, para el que quiera ampliar, le recomiendo que pruebe los modificadores -X y -XX para ver mucha más información. Ahí se puede jugar bastante con segmentos de memoria dinámica y stack, por ejemplo.
Como siempre, un vistazo al man pmap nunca viene mal 😛
En alguna otra oportunidad podemos llegar a ampliar, si hay interés, este tipo de herramientas, ayuda mucho a entender en profundidad el funcionamiento del núcleo Linux!
Finalmente, como se habrá visto, he intentado realizar los ejemplos con códigos C simples, el lenguaje C es ideal para entender este tipo de comportamientos del núcleo. Una base sólida de programación en C para el estándar POSIX.1 sirve mucho.
Se que hoy en día lenguajes como Python han copado el mercado, pero si les interesa este tema me avisan, dependiendo de la demanda puedo armar un curso de C orientado al sistema operativo.
Espero que les haya resultado ameno!
Hasta la próxima!
