Fork Bomb y el apocalipsis zombie en GNU/Linux
En esta oportunidad hablaremos sobre bombas fork, o fork bomb, o cómo un usuario cualquiera puede colgar un sistema Linux saturando la tabla de procesos del sistema.
Tabla de procesos del sistema
Qué es un fork bomb y cómo puede afectar a nuestro sistema Linux?
Antes que nada, una breve introducción conceptual.
En sistemas *nix como Linux, los procesos se crean por clonación de otro proceso ya existente, y mediante diferentes funciones del API POSIX.1, también llamado syscall o interfaz de llamadas al sistema.
Por ejemplo, la ejecución de una función fork() en un programa C generará una clonación del proceso actual y creará un proceso nuevo, que se agregará a la tabla de procesos del sistema, junto con su información, como su PID (Proccess ID), su estado, uptime, etc.
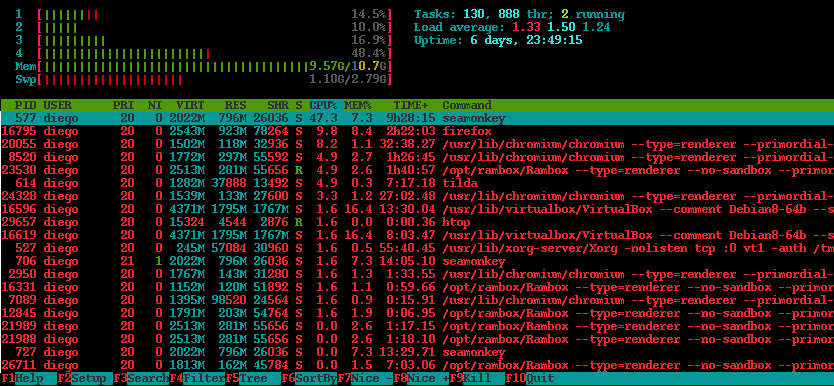
Una bomba fork tiene el objetivo de explotar esta funcionalidad del sistema de manera descontrolada, es decir, la fork bomb creará un proceso, y lo clonará sucesivamente por un tiempo indefinido, de modo que en algún momento la tabla de procesos del sistema se verá saturada y no se permitirá la creación de procesos nuevos.
Ahora bien, por qué no «matar» a la bomba fork luego de que saturó la tabla y volver todo a la normalidad?
Esta pregunta se responde de una manera simple: no se puede. Una vez que la tabla de procesos se ha saturado con una fork bomb que corre en segundo plano, no se podrán ejecutar comandos para listar procesos, ni ejecutar comandos como kill para enviarles señales, puesto que los comandos son programas compilados, y al ejecutarse deben crear procesos, pero como la tabla de procesos está saturada, no podrán siquiera ejecutarse en shell. De hecho, tampoco podremos correr un shell si el sistema ya está saturado.
La fork bomb clásica :(){ :|:& };:
Analicemos la siguiente línea de comandos del shell:
:(){ :|:& };:
Esta línea si se ejecuta en una terminal será capaz de colgar el sistema (si no tomamos ciertas precauciones 🙂 ).
Esa es la definición clásica de una bomba fork por terminal… analicemos la sintaxis por partes.
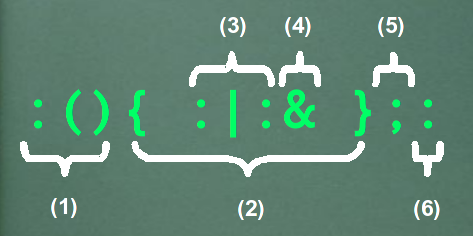
Donde:
- Es la declaración de la función de la shell. «
:« es el nombre de la función, y «()» indica que la función no recibe ningún argumento. - Es la definición de la función, entre llaves. El contenido de las llaves es lo que la función va a ejecutar.
- En el código que la función va a ejecutar, tenemos la llamada a la función, y el resultado se le pasa como entrada via pipes de la línea de órdenes, a otra llamada de la misma función.
La primer ocurrencia de «:« carga en memoria una copia de esta función. Luego con el «|« la salida de la función se le pasa a otra copia de la misma función, por lo que se vuelve a llamar recursivamente. - El símbolo «
&« indica esta llamada a función se va a realizar en segundo plano (background), y tiene por objetivo desacoplar a la segunda llamada de función de la primera, de modo que si el proceso que corre la primer función muere (o lo matan) el proceso de la segunda función continuará su ejecución. - El símbolo «
;« indica que terminamos un comando en la línea de órdenes, y vamos a ejecutar otro en la misma línea. - Por último, el «
:« ejecuta por primera vez a la función definida. Luego, esta ejecución llamara y ejecutará dos veces a la misma función como se explicó en (3). Y así sucesivamente, cada llamada ejecutará a su vez dos veces la misma función… se imaginarán lo que pasa 🙂
Puede resultar más cómodo cambiar el nombre a la función para entenderlo mejor:
funcion(){ funcion | funcion & }; funcion
El apocalipsis zombie en C

En sistemas Unix la creación de procesos se basa en clonación de un proceso anterior. Así, por ejemplo, con fork() estaremos clonando nuestro proceso actual, y generaremos uno nuevo. Dependiendo del valor de retorno de fork() podremos, a nivel de programación, decidir qué tareas va a realizar cada proceso.
Cuando el proceso es generado con fork, se le llama proceso hijo, mientras que el proceso original que ejecutó fork() es el proceso padre.
Lo correcto es que el proceso hijo siempre espere, mediante la syscall wait(), a la terminación del proceso hijo.
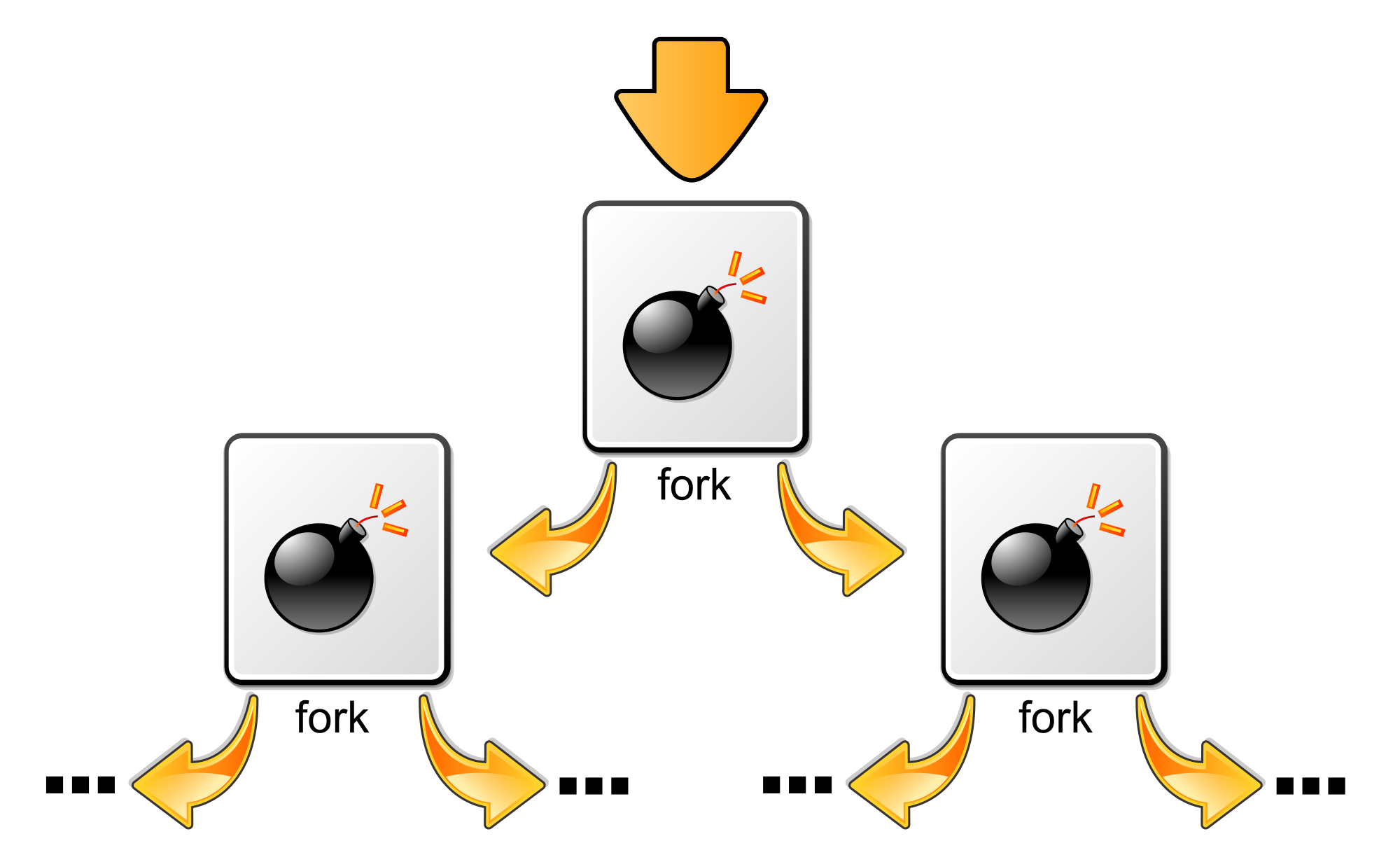
Cuando el proceso hijo termina y el proceso padre sigue trabajando, el proceso hijo queda momentáneamente en estado de «zombie» hasta que el padre recoja su terminación y lo libere utilizando wait().
Ahora, qué pasaría si ejecutamos en un bucle infinito, la función fork(), y a su vez, hacemos que los procesos generados terminen inmediatamente?
Algo así:
#include<unistd.h>
int main(int argc, char** argv){
while(1)
if(!fork()) return 0;
}
Aquí vemos que estamos ejecutando un bucle while infinito, y en cada ciclo ejecutamos una función fork() que genera un proceso hijo del proceso actual.
En el caso de que sea el proceso hijo, fork retornará un valor «0», por lo que entrará al condicional «if» y ejecutará «return 0» para terminar.
El proceso padre seguirá su ejecución, es decir, volverá a ciclar y generará otro hijo.
Como el proceso padre nunca liberó al primer hijo, éste quedó en estado de zombie, y lo mismo ocurrirá con el segundo, y el tercero, y el cuarto, etc.
La única forma de liberar a los procesos zombies es matando al proceso padre, en este caso, el binario compilado de este código fuente.
Si compilamos el código anterior en C y lo ejecutamos, podremos entender cómo nuestro sistema tiende a saturarse de procesos.
La fork bomb en acción
Veamos una animación de ejemplo donde se puede apreciar cómo al ejecutar en segundo plano el binario compilado para generar procesos hijos indiscriminadamente, el sistema se satura de procesos zombies.

Conclusión
Hemos aprendido en este artículo cómo funciona internamente la generación de nuevos procesos en un sistema *nix, y cómo, tanto mediante una línea de comandos en una terminal, como por medio de un código que genera indiscriminadamente procesos en el sistema, podemos saturar nuestra tabla de procesos.
En el siguiente artículo analizaremos algunas medias que podemos implementar a nivel de sysadmin o devops en nuestros servidores para mitigar el efecto de una fork bomb ejecutada por un usuario cualquiera del sistema.
A propósito, les recomiendo algunas lecturas del blog donde hablo sobre procesos y sus estados, prioridades, y características:
- Procesos en Linux, estados y prioridades
- Señales y cómo terminar procesos en GNU/Linux
- Listando procesos del sistema en GNU/Linux
- IPC: Comunicación entre procesos en *nix
¡Espero les resulte interesante!
Hasta la próxima!!