HTTP – ¿Cómo funciona este protocolo?
HTTP es uno de los protocolos TCP/IP de capa de aplicación más utilizado en Internet: Sitios web y API’s REST hacen uso de este protocolo, por lo que es importante entender cómo funciona.
Cuando visitamos cualquier sitio web, el navegador hace uso de HTTP (Hypertext Transfer Protocol – Protocolo de transferencia de hipertexto) para descargar la página desde el servidor.
Es similar a otros protocolos de capa de Aplicación del stack TCP/IP, tales como FTP o SSH, en el sentido que permite a clientes y servidores comunicarse, «entenderse» mediante el envío de mensajes. En el caso de HTTP le permite a un navegador web entenderse con un servidor web.
Además, hoy en día están muy de moda, si se quiere, las aplicaciones que se comunican mediante API’s REST. Un API REST permite a sistemas distribuidos comunicar sus componentes mediante peticiones utilizando el protocolo HTTP.
En fin, es uno de los protocolos más utilizados en la actualidad, por lo que vale la pena echarle un vistazo.
¿Cómo funciona HTTP?
HTTP es un protocolo cliente-servidor que se encapsula dentro de TCP como capa de transporte en TCP/IP. Cliente y servidor pueden comunicarse mediante el envío y recepción de mensajes. HTTP cuenta con los siguientes mensajes, de los cuales en general, los más comunes son GET, POST y HEAD.
No analizaremos en detalle qué hace cada uno de estos métodos, eso lo dejaremos para futuras entradas 😛
- Mensaje GET
El mensaje GET es enviado por un cliente hacia un servidor, indicándole una URL que necesita descargar. El servidor procesa la solicitud y procede a enviarle una respuesta al cliente. El cliente puede incorporar variables adicionales dentro de la URL para parametrizar su consulta al servidor. - Mensaje POST
El mensaje POST es similar a GET, con la diferencia de que los parámetros opcionales que puede enviar el cliente no viajan en la URL de la consulta, sino dentro del cuerpo del mensaje (body). - Mensaje HEAD
Funciona de manera similar a GET, con la diferencia que, en lugar de descargarse todo el contenido de un sitio web solicitado, solamente descarga la cabecera de dicha consulta, contenida dentro de la sección HTML del sitio. - Mensaje PUT
Envía una representación codificada de un recurso específico, no el objeto. A diferencia de POST, sucesivas llamadas a PUT van a enviar la misma representación, mientras que POST puede tener efectos adicionales. - Mensaje DELETE
Borra un recurso puntual. - Mensaje TRACE
Realiza una verificación de loopback, devolviendo el eco de lo que recibió el servidor. - Mensaje CONNECT
Convierte la conexión TCP de la solicitud en un túnel TCP/IP transparente, lo que facilita el cifrado de la comunicación al pasar por proxies. El cliente le solicita al proxy una conexión segura contra un destino, el proxy crea ese túnel contra el destino, y por medio del mismo envía todo el tráfico de ida y vuelta al cliente. - Mensaje OPTIONS
Retorna los métodos HTTP que soporta el servidor para una URL determinada, es decir, le indica al cliente qué puede hacer con un recurso, dependiendo de los permisos.
El cliente iniciará una conexión TCP contra el servidor, apuntando generalmente al puerto 80 de TCP en el servidor, o al 443 en el caso de que se trate de una conexión HTTP segura (HTTPS – HTTP over TLS).
Una vez que se ha establecido la conexión TCP, el cliente envía una solicitud HTTP (por ejemplo, alguno de los mensajes que mencioné arriba), y comienza el intercambio con el servidor.
Una vez que el cliente recibió el resultado de su consulta, se cierra la conexión HTTP con el servidor. Es por esto que a HTTP se lo denomina protocolo sin estado, o stateless. Si el cliente requiere descargar varios sitios web desde un servidor, deberá realizar varias consultas al mismo.
Aquí haremos una breve reseña de cómo funciona HTTP/1.1 con ejemplos de captura, pero si alguien quiere profundizar en los detalles, les dejo la RFC 2616 que documenta todo el protocolo.
Conexiones y estado
Como dije, HTTP es un protocolo que no gestiona estado de las conexiones, y que hace uso de un transporte confiable, TCP, para hacer llegar sus mensajes al destinatario.
En HTTP/1.0, la primera versión del protocolo, se abría una nueva conexión TCP por cada petición que realizaba un cliente al servidor. Como sabemos, en TCP/IP cada nueva conexión requiere un nuevo handshake de inicio, por lo que varios mensajes HTTP se traducían en muchos mensajes TCP en la red, lo que perjudicaba el rendimiento del protocolo.
En HTTP/1.1, una de las versiones más utilizadas hoy en día, esto fue atenuado introduciendo el pipelining y las conexiones, permitiendo a HTTP reutilizar conexiones TCP, controlándolas mediante la cabecera Connection.
Finalmente, HTTP/2 implementa multiplexación de mensajes sobre una misma conexión, incrementando aún más la eficiencia del protocolo.
Por otro lado, y esto como nota adicional, existen experimentos para mejorar más el rendimiento de HTTP, ya no tanto a nivel protocolo de aplicación, sino cambiando su transporte por alternativas como QUIC, que hace uso de UDP, para mantener la fiabilidad del enlace e incrementar la eficiencia. Sí, esto es un tema sumamente interesante del que hablaremos en otra oportunidad 🙂
Funcionamiento del protocolo
Cuando un cliente quiere enviarle un mensaje a un servidor, primero abre una conexión TCP, luego envía su petición, y finalmente recibe la respuesta.
Conexión TCP
El cliente puede enviar una petición o varias dentro de una misma conexión, y también puede abrir varias conexiones contra un servidor HTTP/1.1.
Veamos un ejemplo de un handshake TCP para una conexión HTTP:
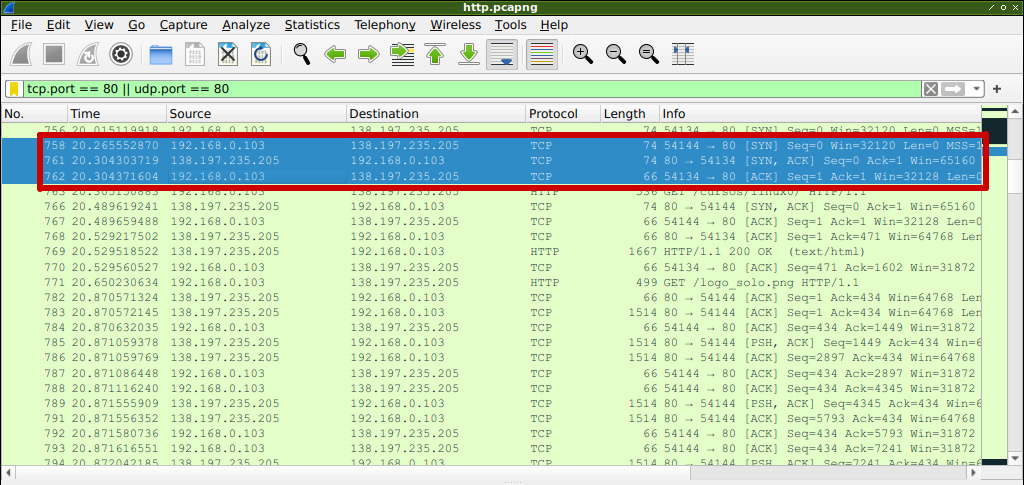
En esta captura he marcado los mensajes correspondientes al handshake de inicio de la comunicación TCP. Ser ve el envío del SYN desde mi computadora hacia un servidor remoto, la respuesta, SYN+ACK, y la respuesta de mi computadora, ACK.
A partir de ese punto comienza la comunicación HTTP, el cliente (mi navegador) envía envía una solicitud al servidor.
Un dato adicional de importancia: el puerto TCP del servidor es el 80, lo que significa que la comunicación es HTTP sin TLS, es decir, sin cifrado (no HTTPS). Y por otro lado, el puerto cliente es el 54144 en este ejemplo. Si bien este es un dato poco relevante, tiene cierta importancia en este ejemplo, como comentaré más adelante.
Solicitud del cliente
Una vez que la conexión se ha creado, el cliente puede enviar su petición HTTP por medio de la misma. Esta petición viaja en texto plano de manera predeterminada. Si bien en HTTP/2 los datos no pueden interpretarse directamente por una cuestión de encapsulado, en HTTP/1.1 sí podemos leer el canal y analizar la información que está viajando por el mismo.
Por supuesto, en cualquier caso, si se hace uso de TLS (HTTPS) el canal será totalmente ilegible para un sniffer de tráfico de red.
Veamos un ejemplo de conexión HTTP/1.1 para aprender a interpretarla correctamente.
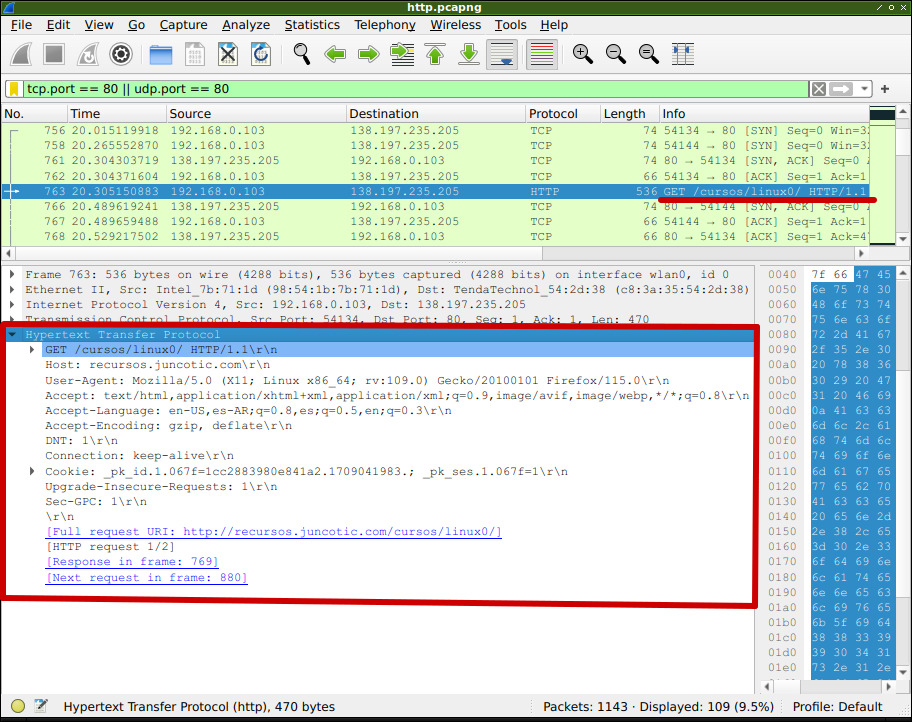
En este ejemplo, el siguiente paquete luego del handshake de TCP, es una solicitud GET enviada desde mi navegador.
En dicha solicitud estoy pidiendo un recurso a través de una URL: recursos.juncotic.com.
Dentro de la request se ve interesante información:
- Se está utilizando HTTP/1.1
- Se ve que el host al que va dirigida la consulta es recursos.juncotic.com.
- El navegador que estoy utilizando fue identificado como Mozilla/5.0 (User-Agent).
- Se ve la lista de los formatos aceptados por el cliente (Accept), entre los que figuran text/html.
- Se ve la lista de los lenguajes aceptados por el cliente (Accept-Language).
- Se ve el header Connection, que, como dijimos, sirve para mantener la conexión TCP activa para varias consultas en HTTP/1.1.
Respuesta del servidor
Los siguientes mensajes TCP mostrados en la captura anterior son propios del funcionamiento de TCP: acuses de recibo y confiabilidad. El siguiente mensaje HTTP que figura en la captura va dirigido desde el servidor hacia mi cliente, y es la respuesta enviada desde el server.
Analicemos algunos datos interesantes:
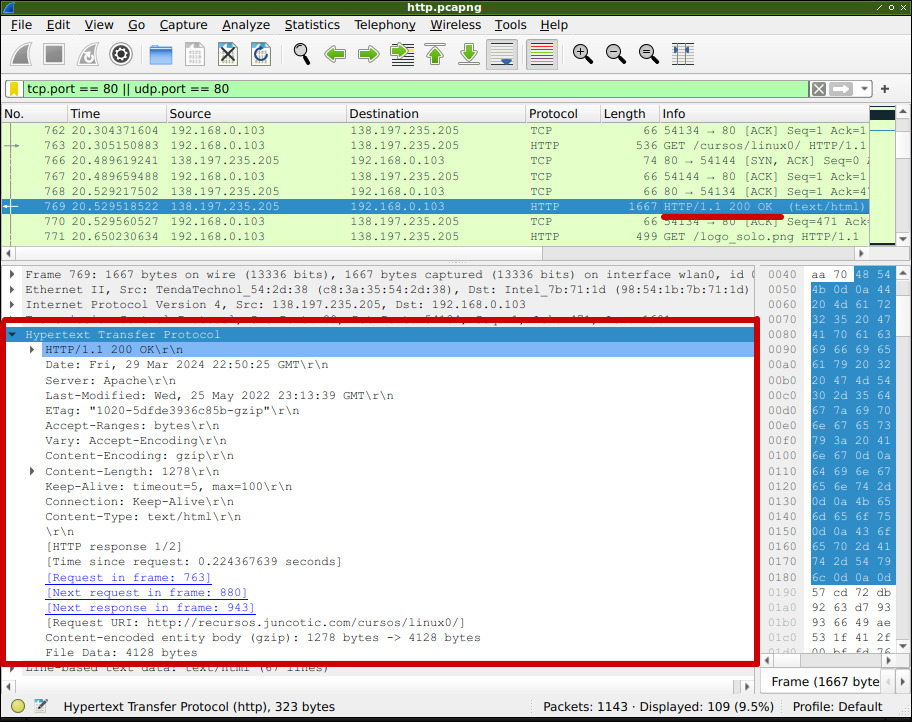
En esta captura se puede ver que el servidor responde con un mensaje 200 OK que, como veremos más abajo, es una respuesta correcta, la solicitud se pudo interpretar correctamente por parte del servidor.
Otra información de interés:
- Se ve la fecha de envío de la respuesta.
- Se ve el campo Server indicando que se trata de un servidor Apache. La versión del servidor no se ve porque la he ocultado en las configuraciones de Apache, por seguridad.
- Muestra la fecha de la última modificación del documento.
- El campo Connection coincide con el del cliente: Keep-Alive.
- Muestra el tipo de documento: text/html, uno de los soportados por el cliente usando el header Content-Type.
Aquí lo principal es entender que el servidor envió una respuesta correcta, código 200, lo que significa que el servidor pudo interpretar sin problemas la consulta, y envió su resultado.
Como dije arriba, el puerto cliente es el TCP 54144, y si revisamos la captura anterior y esta, el tráfico TCP se mantiene en el mismo puerto. La siguiente captura muestra los mensajes posteriores dentro de la misma comunicación:
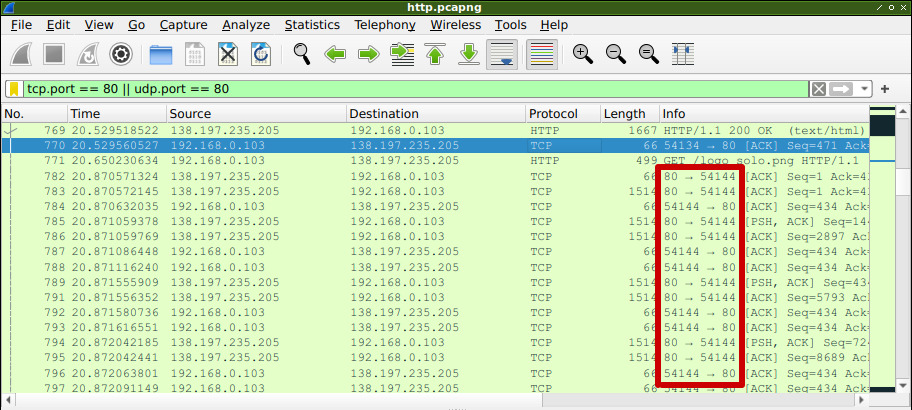
Como se ve, el puerto cliente siempre se mantuvo en 54144 para varias consultas realizadas (además del recurso en text/html, también el cliente descargó una imagen del sitio y el favicon, entre otras cosas).
Esto se da porque HTTP/1.1 mantuvo abierta la conexión TCP establecida al principio, y la utilizó para enviar varias consultas desde el cliente, y esperar sus respuestas desde el servidor.
Analizando un mensaje
Analicemos ahora una consulta HTTP. Para no ser repetitivo, tomemos otra de las consultas realizadas por mi cliente y capturadas con WireShark:
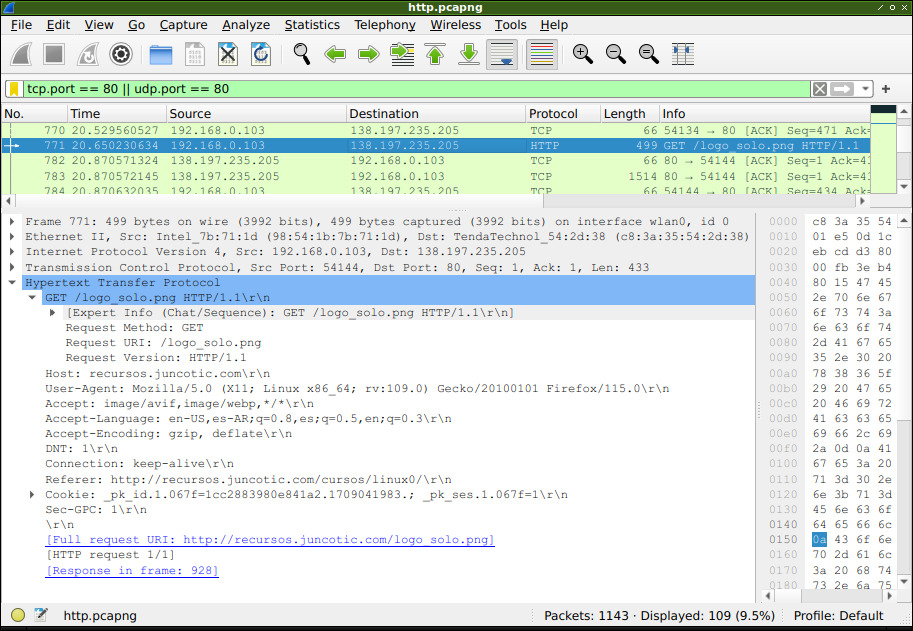
En este caso se trata de una consulta GET para descargar una imagen. En la captura se puede ver que la consulta es la siguiente:
GET /logo_solo.png HTTP/1.1\r\n
Aquí se ve la siguiente información:
- GET hace referencia al método de consulta enviada.
- /logo_solo.png es la ruta, o PATH del recurso consultado.
- HTTP/1.1 es la versión del protocolo que estamos utilizando
Lo siguiente es información de metadatos, conocidos como «headers» de HTTP. Algunos headers incluidos:
- Host: en nombre del servidor al que estamos consultando.
- User-Agent: el cliente de HTTP que estamos utilizando.
- Accept: el tipo de dato que estamos esperando recibir (imagen en este caso).
- Accept-Language: lenguajes soportados por el cliente.
- Accept-Encoding: tipo de codificación de los mensajes soportada.
- Connection: si la conexión es persistente o no (veamos que se trata de la misma conexión TCP de antes).
La respuesta desde el servidor se ve en la siguiente captura:
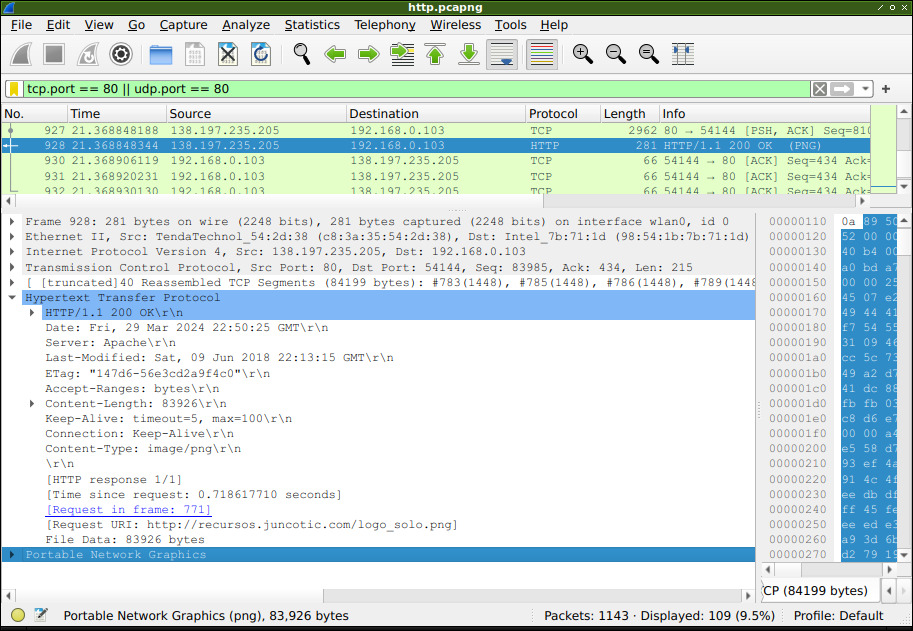
Aquí se aprecia que la respuesta es un 200 OK, o sea, está todo correcto.
Se informa también la versión del protocolo, HTTP/1.1, metadatos y cabeceras opcionales, similar al caso de la consulta comentado antes.
Además, en la respuesta, se incluye una cabecera «Content-Type» que indica que el contenido de datos de dicha respuesta es una imagen de tipo PNG, y al final se ve la cantidad de bytes de dicha imagen, y la imagen propiamente dicha, en bits tal y como viajan por la red, y de acuerdo a lo solicitado por el cliente.
HTTP Troubleshooting y códigos de respuesta
Las consultas enviadas sobre HTTP pueden fallar por varias razones:
- Error en la especificación de la consulta por parte del cliente.
- Mal funcionamiento de cliente o servidor.
- Errores en la generación de las páginas web.
- Problemas temporales de red.
Cuando el servidor responde al cliente siempre envía un código de respuesta. Si la consulta se realiza correctamente el servidor responderá con lo solicitado por el cliente, junto con un código de respuesta satisfactorio.
Si la consulta falla, el servidor responderá con un código de error.
Para identificar los errores y respuestas satisfactorias HTTP provee una nomenclatura estandarizada en su RFC 2616. En resumen, se trata de códigos de 3 dígitos, donde cada uno representa algo en particular.
El primer dígito representa la categoría del mensaje, así:
- 1xx: Mensajes de información, la solicitud fue aceptada y se encuentra en procesamiento.
- 2xx: Confirmación de que la acción se completó correctamente.
- 3xx: Mensaje de redirección, se requiere algo más para completar la solicitud.
- 4xx: Error del cliente, la consulta no puede procesarse, o contiene errores de sintaxis.
- 5xx: Error del servidor, el servidor no pudo completar la consulta, que se supone fue válida.
El segundo y tercer dígito no tienen una categorización especial, sirven para especificar mayores detalles sobre el mensaje.
Así, algunos códigos comunes podrían ser:
- 200: OK, todo se ejecutó correctamente.
- 400: Bad request, hay errores en la consulta realizada por el cliente.
- 401: Unauthorized, se requiere autenticación para acceder a dicho contenido.
- 403: Forbidden, el cliente no tiene permitido acceder a dicho contenido en el servidor.
- 404: Not Found, la consulta que realizó el cliente no puede encontrar resultados en el servidor.
- 500: Internal Server Error, el servidor se encuentra en un estado que no puede resolver.
- 502: Bad gateway, el servidor recibió una respuesta incorrecta mientras intentaba resolver la consulta del cliente.
- 503: Service unavailable, el servidor no puede manejar la consulta realizada por el cliente.
En las capturas anteriores vimos que tanto solicitudes como respuestas se ejecutaron correctamente. Veamos un ejemplo de una solicitud que haya fallado de alguna forma:
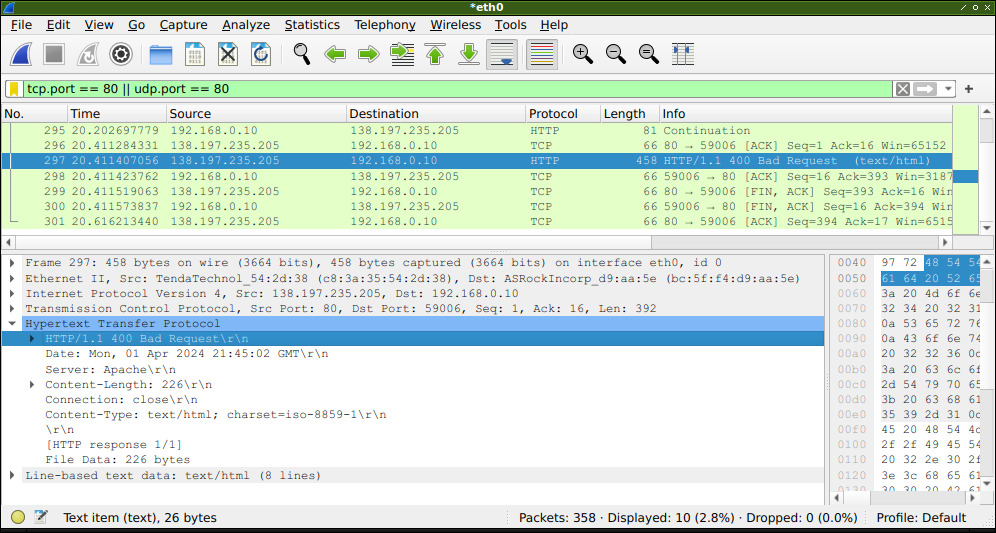
En esta captura se puede ver que la respuesta del servidor es HTTP/1.1, con un código 400 Bad Request, lo que significa que el cliente realizó una consulta que tenía errores.
Conclusiones
Y hemos llegado al final!
Hemos realizado un breve recorrido sobre el protocolo HTTP. En futuras entregas añadiremos contenido adicional, por ejemplo, el uso de clientes de línea de comandos como cURL para formular consultas a servidores web, obtener y analizar sus respuestas.
Además, existe una estrecha relación entre HTTP y la subcapa de cifrado TLS para brindar un tráfico seguro en HTTPS. Eso también es tema que analizaremos más adelante.
Cabe mencionar que este contenido es recurso externo para clases del curso de Redes TCP/IP y protocolos de Internet que dicto desde JuncoTIC. Cualquier información adicional sobre el curso los invito a seguir el enlace 🙂
Espero que les resulte interesante!
Como siempre, ya saben dónde encontrarnos por cualquier consulta, duda o sugerencia.
Hasta la próxima!