Flujo de paquetes en iptables: cómo se procesan las reglas
En esta oportunidad vamos a profundizar sobre cómo se gestiona el flujo de paquetes en iptables, cómo el firewall procesa las reglas, para poder configurarlo correctamente.
Estuve estudiando los flujos de trabajo de los firewalls iptables y nftables en el núcleo Linux, para poder continuar con el curso de nftables y actualizar el curso de iptables, así que voy a resumir aquí algunas de mis notas, y aprovecharé para compartirlas con mis alumnos 🙂
¿Querés saber más de iptables ? Sumate a nuestro curso 📚!
iptables y el orden de las reglas
Como sabemos quienes trabajamos o hemos trabajado con iptables, el orden de las reglas es importante para que el firewall realice las tareas que deseamos.
Ahora bien, ¿a quien no le ha dado dudas el orden de ejecución de las reglas?
Si pongo una regla NAT que modifica una dirección IP, y luego configuro una regla FILTER para analizar ese tráfico, ¿qué dirección IP debo usar en la regla filter? ¿la que traía el paquete originalmente? ¿la nueva IP modificada por el NAT?
Esto puede responderse entendiendo el flujo de paquetes en el firewall.
Una imagen vale mas que mil palabras…
Veamos el siguiente diagrama. Aclaro que tiene algunos detalles erróneos, pero nos sirve para entender cómo funciona iptables.
Centremos nuestra atención en la capa 3 del modelo TCP/IP, la capa de red. Imaginemos que iptables trabaja en esta capa… sí, ya se que permite análisis de tráfico con datos de protocolos de otras capas, pero para entenderlo nos viene bien.
A la derecha he colocado el stack TCP/IP, y a la izquierda una ampliación de la capa de red, donde he incluido el flujo de trabajo básico (y un tanto incompleto) de iptables.
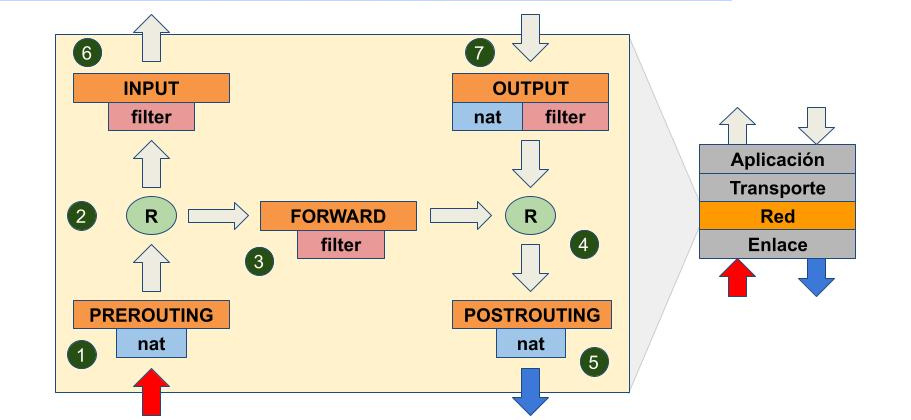
El flujo de paquetes en iptables
Cuando un paquete llega al equipos que corre iptables, viene por la red, por el medio físico, pasa a capa de Enlace de datos, y luego se desencapsula y pasa a capa de Red, donde es procesado por iptables.
En la imagen, el paquete entrante llega donde indica la pequeña flecha roja en la parte inferior.
Si no saben qué es estos de las capas, el encapsulado, TCP/IP y conceptos básicos de redes, los invito a sumarse al curso de Redes TCP/IP y protocolos de Internet.
1) nat PREROUTING
Una vez que el paquete entra, lo primero que se realiza es analizar las reglas de la tabla nat, con cadena PREROUTING.
Se denomina así, PREROUTING, porque se analizan antes de tomar la primer decisión de ruteo o enrutamiento (marcada con una R en el diagrama).
En el caso de que tengamos reglas configuradas aquí, podremos cambiar, por ejemplo, la dirección IP de destino del tráfico entrante.
Si no hay reglas en nat PREROUTING, no se realiza ninguna tarea, y el paquete sigue su curso.
2) Primer decisión de enrutamiento
En este punto se analiza la dirección IP destino del paquete para determinar quién es el destinatario.
Básicamente, el curso cambia si la dirección IP de destino coincide con alguna de las direcciones IP configuradas en el equipo, o no.
- Si la IP destino del paquete coincide con alguna dirección IP configurada en el firewall, indica que el paquete está destinado al propio firewall, se considera INPUT.
- Si la IP destino del paquete no coincide con ninguna dirección IP configurada en el firewall, indica que el paquete está destinado a otro nodo de la red, es un paquete de paso, y se considera FORWARD.
A partir de aquí continúa el análisis por uno u otro camino.
3) Si el paquete es FORWARD
En el caso de que, al tomar la decisión de enrutamiento, el paquete esté destinado a otro equipo de la red, antes de reenviarlo, se analizarán las reglas de la cadena FORWARD de la tabla filter.
Al analizar estas reglas se determinará si se descarta el paquete, se acepta, o se realiza alguna otra acción. En el caso de que se descarte, simplemente se elimina del flujo de trabajo.
En el caso de que se acepte el paquete, continuará su curso a la segunda decisión de enrutamiento.
En el caso de que no hayan reglas configuradas aquí, se ejecutará la política predeterminada de la tabla filter, que podrá descartar o aceptar el paquete.
4) Segunda decisión de enrutamiento
Aquí se determinará hacia dónde va destinado el paquete, y se procederá a ejecutar el algoritmo de enrutamiento del sistema.
Ya sabemos que el paquete va a salir a la red, solamente se va a determinar a qué host irá: un host local de la LAN, una puerta de enlace particular, o la puerta de enlace predeterminada.
Una vez tomada la decisión de enrutamiento, el paquete sigue su curso.
5) nat POSTROUTING
Finalmente, el paquete pasa por el conjunto de reglas de la tabla nat, con la cadena POSTROUTING, luego de la decisión de enrutamiento.
Aquí podremos cambiar algunos parámetros del paquete, por ejemplo, la dirección IP origen del mismo, cuando estamos realizando NAT o enmascarando tráfico.
Si no hay reglas, obviamente no se ejecutará nada, y el paquete seguirá su rumbo hacia la capa 2 de enlace de datos.
6) Si el paquete es INPUT
Si el paquete es de tipo INPUT, es decir, si luego de la primer decisión de enrutamiento vemos que está dirigido a una IP del firewall, se analizarán las reglas cargadas en la tabla filter, con la cadena INPUT.
Al analizar estar reglas de la tabla filter se podrá descartar o no el paquete.
Si se descarta, simplemente se elimina, sin se realizar ningún procesamiento posterior.
Si se acepta, pasará a capas superiores, Transporte, y Aplicación, donde será procesado convenientemente.
Por ejemplo, si un nodo de la red intenta conectar con un servicio SSH corriendo en el firewall, estos paquetes que entran serán considerados INPUT, y serán aceptados (o no) en esta instancia. SI se aceptan, serán procesados por el servicio SSH del equipo.
Nota al margen: aquí también se analizan las reglas nat de INPUT, pero vamos a omitirlo, al menos de momento.
7) Si el paquete es OUTPUT
Si el paquete es OUTPUT, es decir, se trata de un paquete generado en el ordenador, en capas superiores, y sale del mismo con otro destino, se analizarán las reglas de la cadena OUTPUT de la tabla nat, y luego las reglas de la cadena OUTPUT de la tabla filter.
Las reglas de la tabla nat, cadena OUTPUT nos permitirán cambiar direcciones IP, puertos, etc., mientras que las reglas de la tabla filter para dicha cadena nos permitirán descartar el paquete, o dejarlo seguir su rumbo.
En el caso de que el paquete sea descartado, simplemente se elimina.
En el caso de que el paquete sea aceptado, continuará su rumbo hacia la segunda decisión de enrutamiento, punto (4), y luego se verificarán las reglas de la cadena POSTROUTING de la tabla nat, punto (5).
Cabe aclarar que el paquete saliente, OUTPUT, puede ser un paquete nuevo creado en el firewall, por ejemplo, por un cliente de protocolo de capa de aplicación, o puede ser un paquete que un servidor de protocolo de capa de aplicación está enviando como respuesta a una consulta que hizo un cliente remoto, y que, en su momento, fue tráfico INPUT.
¿Querés saber más de iptables ? Sumate a nuestro curso 📚!
Un par de ejemplos de flujo de paquetes en iptables
Supongamos en primera instancia que tenemos un firewall configurado en nuestro equipo GNU/Linux, y tenemos, por ejemplo, un servidor web corriendo allí.
Este equipo a su vez tiene acceso a Internet con IP pública, y los clientes de Internet pueden consultar los sitios web de nuestro servidor… algo así:

Si un cliente en Internet realiza una consulta HTTPS a nuestro servidor local, ese paquete de consulta será INPUT, se procesará y se generará la respuesta.
El paquete seguirá el flujo de tráfico INPUT descripto anteriormente: (1) -> (2) -> (6).
El servidor web procesará la consulta y generará la respuesta. Esa respuesta será uno o varios paquetes OUTPUT, y seguirán el flujo de trabajo (7) -> (4) -> (5).
Ahora bien, si el firewall que estamos configurando divide una LAN de Internet, o simplemente está en medio de la conexión entre un cliente y la red de redes… algo así:
Y el cliente realiza una consulta HTTPS a un servidor que se encuentra en Internet, ese tráfico será FORWARD para nuestro firewall, por lo que la consulta seguirá el flujo de trabajo: (1) -> (2) -> (3) -> (4) -> (5).
Ahora bien, la respuesta desde el servidor web también será tráfico que «pase» por el firewall hacia el cliente, por lo que seguirá el mismo flujo de trabajo que la consulta.
Conclusiones
Hemos visto cómo es el flujo de paquetes en iptables, el firewall tradicional de Linux.
iptables utiliza las tablas y cadenas y hooks definidas por el framework netfilter, por eso es que siempre son fijas las tablas filter, nat y mangle, y las cadenas INPUT, OUTPUT, FORWARD, PREROUTING y POSTROUTING.
¿Esto aplica también a nftables?
Si y no. En general sí, ya que ambos funcionan sobre netfilter, y utilizan los mismos hooks en los puntos del flujo de trabajo mencionado anteriormente: INPUT, OUTPUT, FORWARD, PREROUTING y POSTROUTING.
Además, ambos analizan linealmente los paquetes, aunque nftables permite estructuras de análisis más complejas.
Pero, a diferencia de iptables, nftables no tiene tablas predefinidas, sino que son todas tablas creadas por el usuario. Lo mismo ocurre con las cadenas, también son definidas por el usuario.
Si les interesa profundizar sobre las diferencias entre iptables y nftables, aquí tienen un par de posts:
En fin, si la pregunta es: ¿este flujo de paquetes en iptables es el mismo para nftables?, la respuesta es: sí, pero con algunos matices.
- En iptables las reglas se distribuyen en tablas predefinidas, con cadenas asociadas a cada hook.
- En nftables las tablas y cadenas son definidas por el usuario, conectadas a los hooks de netfilter, lo que permite estructuras más flexibles para decidir el destino de cada paquete.
Espero que se haya entendido!
Como siempre, me consultan en el grupo de Telegram cualquier duda!