GlusterFS: montando nuestro sistema de archivos distribuido
En esta oportunidad conoceremos algunas características de un sistema de archivos distribuido en red, y montaremos nuestra prueba de concepto con bricks GlusterFS en un esquema replicado.
Introducción a GlusterFS
GlusterFS es un sistema de archivos basado en software libre (GPLv3), escalable y distribuido en red para montar un NAS (Network Attached Storage). Resulta muy útil y flexible para almacenamiento en computación de nube. Fue desarrollado inicialmente por Gluster Inc., compañía adquirida por RedHat en el año 2011.
Se basa en servidores de almacenamiento distribuidos sobre redes Ethernet generalmente, en una gran red de sistema de archivos paralelo. Se compone de dos partes:
- Servidor: desplegado generalmente como bricks o bloques de almacenamiento, en el que cada servidor corre el daemon glusterfsd para exportar a la red un volumen de datos, asociado a su brick.
- Cliente: Proceso que conecta al servidor sobre una red TCP/IP (en general), creando un volumen virtual de datos compuesto por volúmenes remotos importados desde varios servidores. El cliente monta el volumen compuesto usando el protocolo GlusterFS nativo en GNU/Linux por medio de la interfaz FUSE (sistemas de archivos de nivel de usuario) o el protocolo NFSv3. A su vez el cliente puede re-exportar el volúmen utilizando NFSv4, SAMBA u almacenamientos de datos Swift de OpenStack.
Entre las funcionalidades que brinda GlusterFS se encuentran el stripping o distribución de archivos en diversos servidores, el mirroring o replicación de datos en diferentes servidores, el balanceo de carga, la implementación de caché de datos, cuotas de almacenamiento, y snapshots de volúmenes. La replicación que permite utilizar GlusterFS asegura que exista al menos una copia de los archivos en el cluster de bricks.
El servidor se mantiene relativamente simple: exporta un directorio local como si fuera un dispositivo de bloques de almacenamiento. Esta arquitectura permite que el volumen de datos GlusterFS pueda escalar a varios petabytes de información de manera ágil sin cuellos de botella en su funcionamiento.
Entre otras características, está disponible para cualquier sistema GNU/Linux, y es compatible con el estándar POSIX, por lo que se pueden montar y trabajar los volúmenes como si fueran dispositivos de bloque locales, así se pueden utilizar herramientas como mkfs o mount directamente sobre volúmenes GlusterFS.
Arquitectura de GlusterFS
Como dijimos, GlusterFS dispone servidores en la red, que corren el daemon glusterfsd. Cada servidor puede alojar los bricks, unidades básicas de almacenamiento del cluster. El brick en un servidor GlusterFS es un directorio exportado a la red, para que pueda ser «importado» y utilizado por clientes. Para quien ha trabajado con NFS resultará familiar el esquema, un brick sería el equivalente a un directorio NFS exportado a la red (exports). Así, el acceso a un brick de un servidor determinado puede ubicarse mediante la URI SERVER:EXPORT, por ejemplo, si en el servidor Gluster1 tenemos exportado el brick /exports/brick1, un equipo de la red podría ubicar dicho brick utilizando la URI Server1:/exports/brick1.
Para mejorar el rendimiento, y facilitar la administración, los bricks en general se montan sobre volúmenes lógicos de LVM. Así, por ejemplo, en un servidor podríamos añadir un nuevo disco rígido, agregarlo al grupo de volúmenes LVM como volumen físico, y luego extender el volumen lógico sobre el que está montado el brick, de manera transparente y casi instantánea para los usuarios.
Veamos algunos de los esquemas más comunes de volúmenes de red de GlusterFS:
- Volúmenes distribuidos
- Volúmenes replicados
- Volúmenes Mixtos (distribuidos y replicados)
Volúmenes glusterfs distribuidos
Este esquema no provee redundancia, los archivos se almacenan en los bricks que se encuentren disponibles en la red. Sería el equivalente a un RAID-0 (Stripe). Se trata del esquema de volúmenes configurado de manera predeterminada.
La siguiente figura muestra un volumen distribuido con dos servidores, un brick por servidor. Si los bricks son del mismo tamaño, llamémosle SIZE, el espacio total de almacenamiento en el volumen GlusterFS será de 2*SIZE.
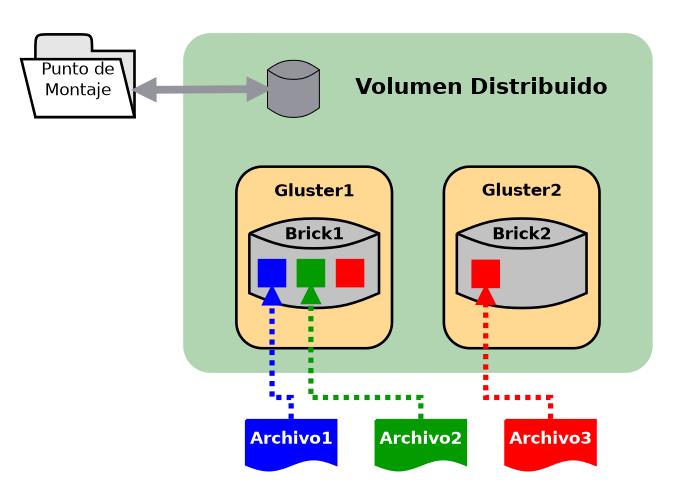
Volúmenes glusterfs replicados
Los volúmenes replicados sí proveen redundancia de datos, al estilo Raid-1 (Mirror). Durante la creación del cluster de datos se especifican las réplicas que vamos a utilizar. Como mínimo se requieren dos bricks para tener dos réplicas del mismo volumen.
La siguiente figura muestra un volumen replicado con dos servidores. Si los bricks son del mismo tamaño, llamémosle SIZE, el espacio total de almacenamiento en el volumen GlusterFS será de SIZE.
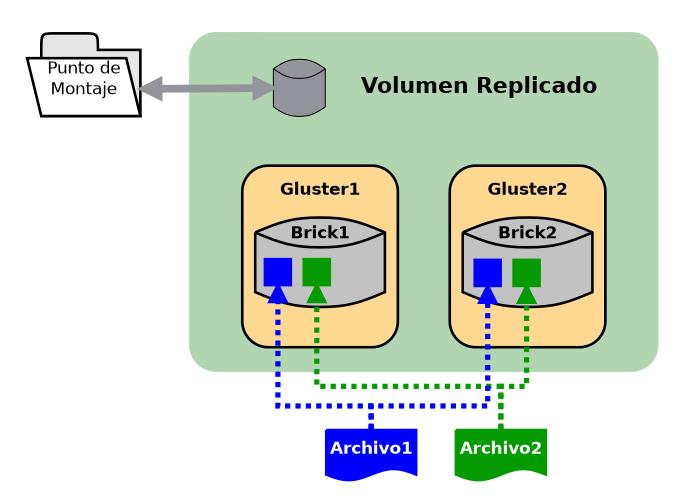
Volúmenes mixtos (distribuidos y replicados)
Los volúmenes mixtos permiten ambas características: ser distribuidos en red, y a su vez proveer redundancia de datos. Como en el caso anterior, durante la creación del cluster se definen las réplicas.
La siguiente figura muestra un volumen distribuido y replicado, dos servidores/briks conforman el primer volumen replicado, y otros dos servidores/bricks el segundo volumen replicado. A su vez, los archivos se van distribuyendo en la red en uno u otro volumen replicado.
A este esquema GlusterFS lo denomina 2×2, es decir, dos volúmenes replicados con dos bricks cada uno. Si los bricks son del mismo tamaño, llamémosle SIZE, el espacio total de almacenamiento en el volumen GlusterFS será de 2*SIZE. Otro esquema posible sería, por ejemplo, un esquema 1×4, en el que tendríamos un solo volúmen replicado cuatro veces, y el tamaño completo del cluster sería SIZE.

Un ejemplo práctico
A modo de ejemplo, vamos a montar un volumen replicado GlusterFS. GlusterFS puede montar sus bricks en cualquier sistema GNU/Linux sobre cualquier infraestructura (instancias cloud, máquinas virtuales, servidores on-premises. En mi caso particular voy a utilizar servidores Ubuntu 18.04 corriendo en una nube privada sobre OpenStack. Además, utilizaré otro Ubuntu como cliente para montar el volumen distribuido. Los equipos en cuestión y sus direcciones IP son:
- Gluster1 (10.201.2.226)
- Gluster2 (10.201.2.243)
- test1 (cliente, 10.201.0.29)
Los dos servidores poseen un disco virtual añadido, /dev/vdb. Como mencionamos arriba, vamos a trabajar con bricks sobre LVM, por lo que los pasos para completar esta práctica serán los siguientes:
- Configurar la resolución de nombres (todos los servidores)
- Crear una partición primaria en el disco añadido (todos los servidores)
- Crear un volumen físico de LVM con dicha partición (todos los servidores)
- Crear un grupo de volúmenes lógicos LVM (todos los servidores)
- Crear un volumen lógico LVM del espacio completo del grupo (todos los servidores)
- Crear un sistema de archivos xfs para dicho volumen lógico (todos los servidores)
- Montar dicho sistema de archivos en un punto de montaje (todos los servidores)
- Crear el brick dentro del punto de montaje (todos los servidores)
- Reiniciar el daemon glusterfsd (todos los servidores)
- En uno de los servidores (generalmente el primero) añadimos a los otros servidores (esta operación es sincrónica, por lo que los demás servidores a partir de este momento también serán «conscientes» del volumen glusterfs.
- Montar el volumen glusterfs en el cliente, y verificar la replicación de archivos.
Manos a la obra!
1. Resolución de nombres
Los servidores GlusterFS van a encontrar a los otros servidores mediante un nombre, lo cual es recomendable en el caso de que cambien las direcciones IP, ya que actualizando los nombres bastaría.
En mi caso, para no añadir complejidad, realicé la resolución básica mediante el clásico archivo /etc/hosts. En cada servidor, y en el cliente, he agregado lo siguiente a dicho archivo:
# /etc/hosts
[...]
10.201.2.226 gluster1
10.201.2.243 gluster2
2. Crear la partición en el disco añadido
En cada servidor tengo un disco nuevo, /dev/vdb, para crear la partición y dejarla apta para su uso en LVM, he corrido los siguientes comandos en cada uno de los servidores (usé una tabla de particiones GPT).
parted -s -- /dev/vdb mktable gpt
parted -s -- /dev/vdb mkpart primary 2048s 100%
parted -s -- /dev/vdb set 1 lvm on
3-4-5. Crear el esquema LVM
Ahora vamos a crear un volumen físico con la partición del disco añadido, un grupo de volúmenes lógicos al que he llamado vgglus-01, que incluye dicho volumen físico:
# creamos un volumen físico LVM:
pvcreate /dev/vdb1
#creamos un grupo de volúmenes llamado vgglus-01
# que incluya al volumen físico previamente creado:
vgcreate vgglus-01 /dev/vdb1
Luego creamos el volumen lógico del tamaño total del grupo de volúmenes de LVM. Los volúmenes lógicos tienen nombres. Los he llamado gbric1 y gbric2 para los servidores gluster1 y gluster2 respectivamente. La línea de comandos es equivalente.
# En el caso del servidor gluster1:
lvcreate -l 100%VG -n gbric1 vgglus-01
# En el caso del servidor gluster2:
lvcreate -l 100%VG -n gbric2 vgglus-01
6-7. Creando el filesystem y montándolo
En ambos servidores creé el sistema de archivos XFS de la misma manera, usando mkfs. ¿Por qué xfs? Como requisito, GlusterFS trabaja sobre sistemas de archivos que soporten atributos extendidos (extended attributes – xattr), puede correr sobre cualquier filesystem que lo soporte (ext4, zfs, xfs, reiserfs, etc).
Particularmente XFS permite configurar el tamaño de los inodos. Por defecto XFS setea los inodos en 256 bytes, pero GlusterFS tiene mejor rendimiento con inodos de 512 bytes, por lo que he configurado esto con el modificador -i en mkfs.
Además, el tamaño por defecto de los bloques destinados a directorios es de 4 KiB. XFS permite incrementar dicho tamaño para mejorar el rendimiento en GlusterFS. Eso lo he configurado con el modificador -n en mkfs. Particularmente lo he seteado al doble, 8KiB (8192 bytes).
Con estas opciones básicas deberíamos tener un GlusterFS con un rendimento medianamente óptimo en red.
# En el servidor gluster1:
mkfs.xfs -i size=512 -n size=8192 /dev/vgglus-01/gbric1
# En el servidor gluster2:
mkfs.xfs -i size=512 -n size=8192 /dev/vgglus-01/gbric2
Creé el punto de montaje para el volumen glusterfs donde monté luego el volumen lógico en cada servidor:
# En ambos servidores:
mkdir /var/lib/gvol0
Para realizar el montaje se puede usar el comando mount o agregar la entrada correspondiente en el archivo /etc/fstab de modo que sea persistente entre reinicios del servidor. Como el filesystem utilizado es xfs, disponemos de algunas opciones adicionales de montaje que permiten optimizar el rendimiento.
Uno de los parámetros que podemos configurar es la estrategia de asignación de los inodes. XFS soporta dos opciones:
inode32: XFS almacena todos los inodes en el primer TiB de almacenamiento del disco. Si el disco es grande, esto puede resultar un cuello de botella. Esta es la opción predeterminada.inode64: en este caso los inodes se almacenan cercanos a la ubicación de los datos, lo que reduce las búsquedas (seek) dentro del disco. Esta opción sería más conveniente en nuestro caso. Puede configurarse con la opción-oen las configuraciones de montaje.
Por otro lado, si las aplicaciones que usemos no requieren administrar el tiempo del último acceso a disco (la mayoría de las aplicaciones no lo necesitan), podemos desactivar la actualización de dicho tiempo mediante la opción noatime, evitando que se realice una operación de escritura en el sistema de archivos cada vez que se quiera leer un archivo. Este detalle es válido para casi cualquier sistema de archivos, y ya lo hemos comentadio con anterioridad en el blog.
Para montar el volumen con estas opciones podríamos ejecutar el comando mount de la siguiente manera:
# En el servidor gluster1:
mount -t xfs -o inode64,noatime /dev/vgglus-01/gbrick1 /var/lib/gvol0
# En el servidor gluster2:
mount -t xfs -o inode64,noatime /dev/vgglus-01/gbrick2 /var/lib/gvol0
El equivalente usando el archivo /etc/fstab para mantener la persistencia sería:
# En el servidor gluster1:
echo '/dev/vgglus-01/gbrick1 /var/lib/gvol0 xfs defaults,inode64,noatime 0 0' >> /etc/fstab
# En el servidor gluster2:
echo '/dev/vgglus-01/gbrick2 /var/lib/gvol0 xfs defaults,inode64,noatime 0 0' >> /etc/fstab
Si está la línea cargada en el fstab, podríamos montar el sistema de archivos con algo como ésto:
# En ambos servidores:
mount /var/lib/gvol0
8. Crear los bricks
Como mencionamos antes, los bricks no son más que directorios del sistema de archivos que serán «exportados» a la red mediante glusterfs. Así, dentro del directorio montado en cada servidor, creé un subdirectorio llamado brick1 y brick2 respectivamente:
# En el servidor gluster1:
mkdir /var/lib/glus0/brick1
# En el servidor gluster2:
mkdir /var/lib/glus0/brick2
9-10. Administrar el GlusterFS
Ahora habilitamos y ejecutamos el daemon glusterd en cada servidor:
systemctl enable glusterd
systemctl start glusterd
Generalmente en el primer servidor conectamos con los otros servidores glusterfs. En este caso tenemos dos servidores, gluster1 y gluster2, por lo que en la consola de gluster1 añadimos al servidor gluster2 de esta forma:
gluster peer probe gluster2
Ahora podemos ver el estado del sistema de archivos distribuido con:
gluster peer status
La salida de este comando debería mostrar la cantidad de nodos conectados, el nombre de los otros nodos, el UUID del volumen asociado a cada nodo, y el estado en el que se encuentra. Por ejemplo, la siguiente figura muestra la salida de dicho comando para los dos nodos, gluster1 y gluster2, y puede verse que ambos apuntan al otro nodo:
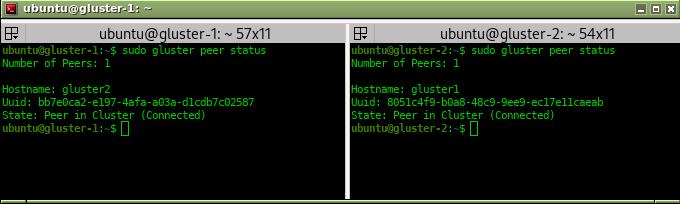
También tenemos un comando para listar, en cada servidor, los otros UUID’s de glusterfs conectados:
gluster pool list
La salida, para nuestros dos servidores, podría verse así:
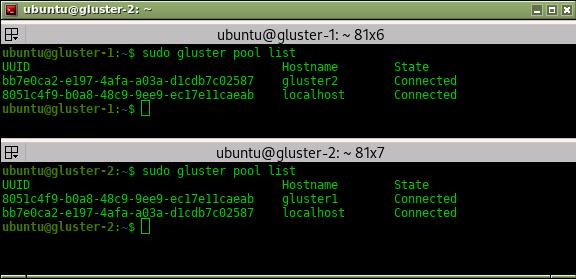
Otro comando útil es el que nos permite listar los volúmenes glusterfs activos (en cualquiera de los servidores).
gluster volume list
Eso nos dará el nombre del volumen GlusterFS, en nuestro caso, gvol0. Ahora podremos ver la información del mismo con el siguiente comando:
gluster volume info gvol0
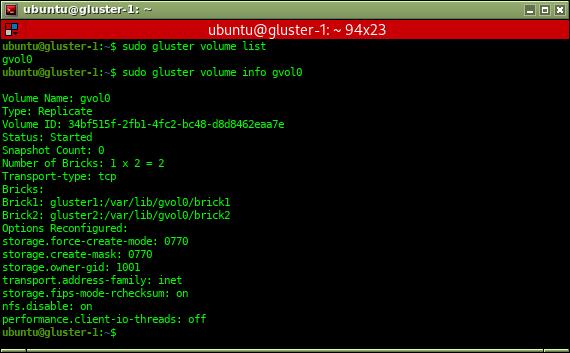
11. Conectando el cliente
Finalmente, vamos a conectar un cliente y vamos a montar el volumen glusterfs en un punto de montaje para poder utilizarlo.
El cliente, test1 en este caso, podría montar el volumen distribuido a través de uno de los servidores que lo comparten. Supongamos que vamos a utilizar el primer servidor, gluster1. Recordemos que la ruta completa al volumen compartido es del tipo SERVER:/volumen, así, el volumen glusterfs, llamado gvol0, que incluye los bricks brick1 y brick2, accedido a través del servidor gluster1 tendría una URI como la siguiente:
gluster1:/gvol0
El cliente montará el sistema de archivos remoto en un punto de montaje… llamémosle /mnt/gvol0:
mkdir /mnt/gvol0
Como el cliente puede resolver el nombre gluster1 por medio del archivo /etc/hosts como se mencionó en el punto (1), podemos agregar la siguiente línea en el archivo /etc/fstab para montar el dispositivo:
echo 'gluster1:/gvol0 /mnt/gvol0 glusterfs _netdev 0 0' >> /etc/fstab
Esta línea indica que el volumen «gluster1:/gvol0» se montará en el directorio «/mnt/gvol0» con el sistema de archivos glusterfs. La opción «_netdev» le indica al sistema que se trata de un sistema de archivos de red, para que gestione de manera adecuada los timeouts de las operaciones de entrada/salida.
Finalmente, no queda mas que montar el sistema de archivos:
mount /mnt/gvol0
Si lo queremos hacer de manera volátil, sin modificar el archivo /etc/fstab, podríamos correr simplemente este comando:
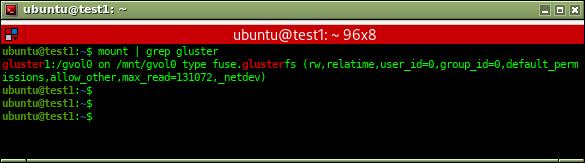
mount -o _netdev -t glusterfs gluster1:/gvol0 /mnt/gvol0/
De esta forma tendríamos el volumen remoto montado, como se puede ver en la siguiente figura:
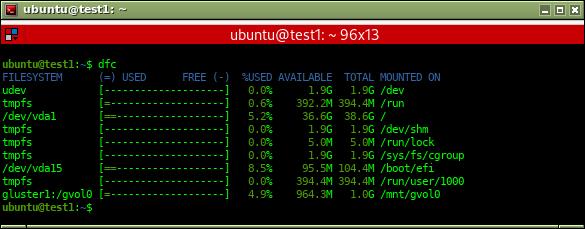
A su vez, también puede verse el volumen montado como un nuevo disco en herramientas como df o dfc:
Y por último, la prueba de concepto de la escritura de datos en el sistema de archivos distribuido y, particularmente en este ejemplo, la replicación en ambos bricks:
Conclusiones
Hemos llegado al final! Pudimos configurar un sistema de archivos distribuido y replicado GlusterFS con dos servidores con sus bricks, y un cliente de prueba.
Si bien les he comentado algunas opciones que mejoran el rendimiento usando XFS, los invito a visitar este sitio, en el que detallan más parámetros al respecto, incluidas configuraciones de replicación.
Les dejo otra serie de artículos interesantes que leí mientras escribía este:
- Get started with GlusterFS – considerations and installation
- Red Hat Gluster Storage: Administration Guide
- How to install and configure GlusterFS on Debian 10?
- Tutorial: What is GlusterFS shared storage and types of volumes
- Split brain and the ways to deal with it
Sin más, espero que esta entrada les guste y les resulte interesante! Cualquier duda o comentario recuerden que pueden sumarse y comentar en la comunidad de JuncoTIC en Telegram!
Y por supuesto, también pueden sumarse en nuestras redes sociales 🙂
¡Hasta la próxima!